这是第二次读DDIA,全名叫做《Design Data-Intensive Application》 直译为:设计数据密集型应用或数据密集型应用的设计;更多精彩内容,欢迎关注微信公众号:stackoverflow
🎈为什么分享这本书🎈
我相信各位一定历经过这样的场景:春节档档期一下子上映了很多场电影,一场电影要不要去看呢?对于我来说,通常都是先看一下豆瓣评分,如果高的话,就买票入场,所以为什么选择分享这本书,那就不得不说下这本书的溢美之词
关于ddia的溢美之词
可以看到,这本书的评价惊人的高,居然达到了 9.7分的高分,有的同学可能觉得9.7分并不是一个很高的分数,来看下面这部是个码农都知道的书《算法导论》,这本书的评分是多少呢? 9.2分,当然这是一个很高的分数,但是ddia 比这个高度还要高 0.5分;有的同学可能还是不能很直接的get到这本书的魅力,OK,我们来和豆瓣电影评分类比一下,要知道豆瓣中电影评分最高的也就是9.7分,也就是大名鼎鼎的,我相信各位应该都看过《肖申克的救赎》
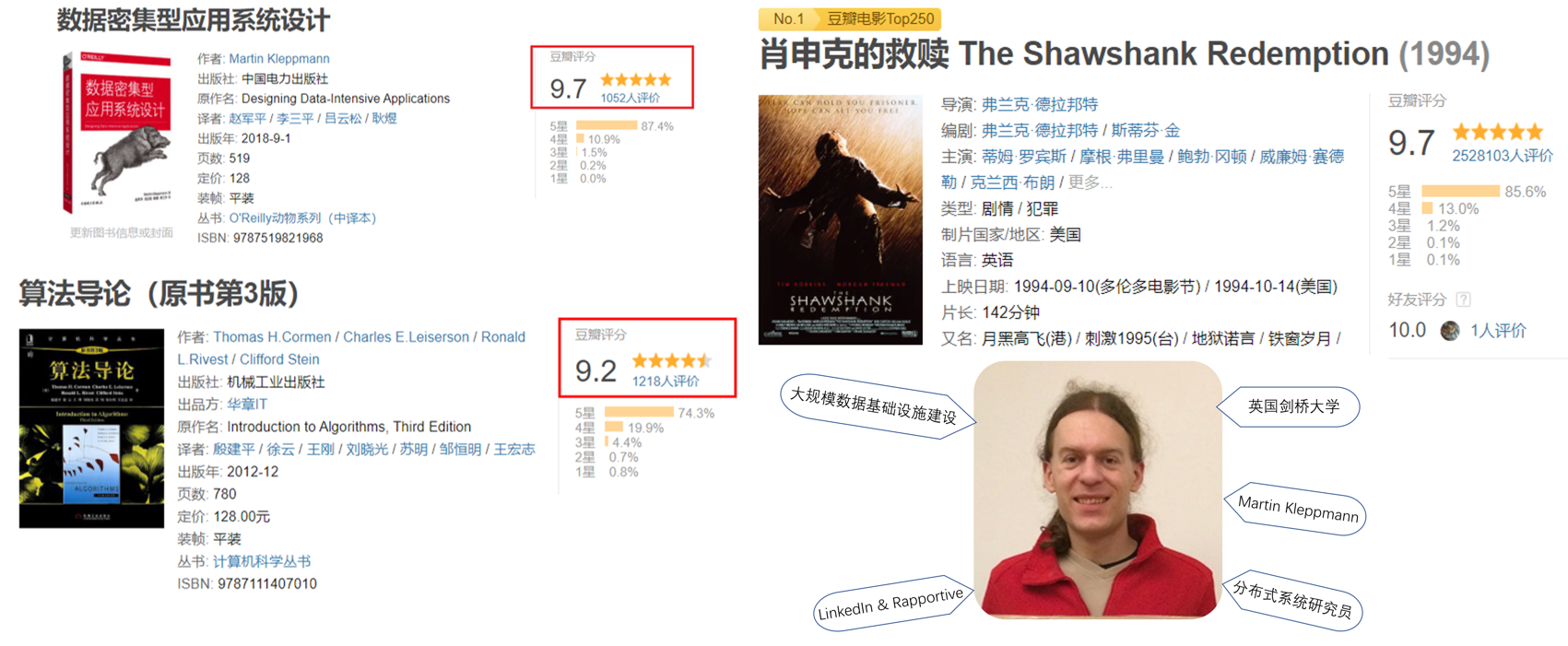
设计数据密集型应用的赞美之词
甚至ByteDance 这家公司将这本书写进入interview doc。所以结论来了,DDIA , 你值得拥有
关于作者
整书大纲
下面是整书的一个脉络:分为3个部分12个章节
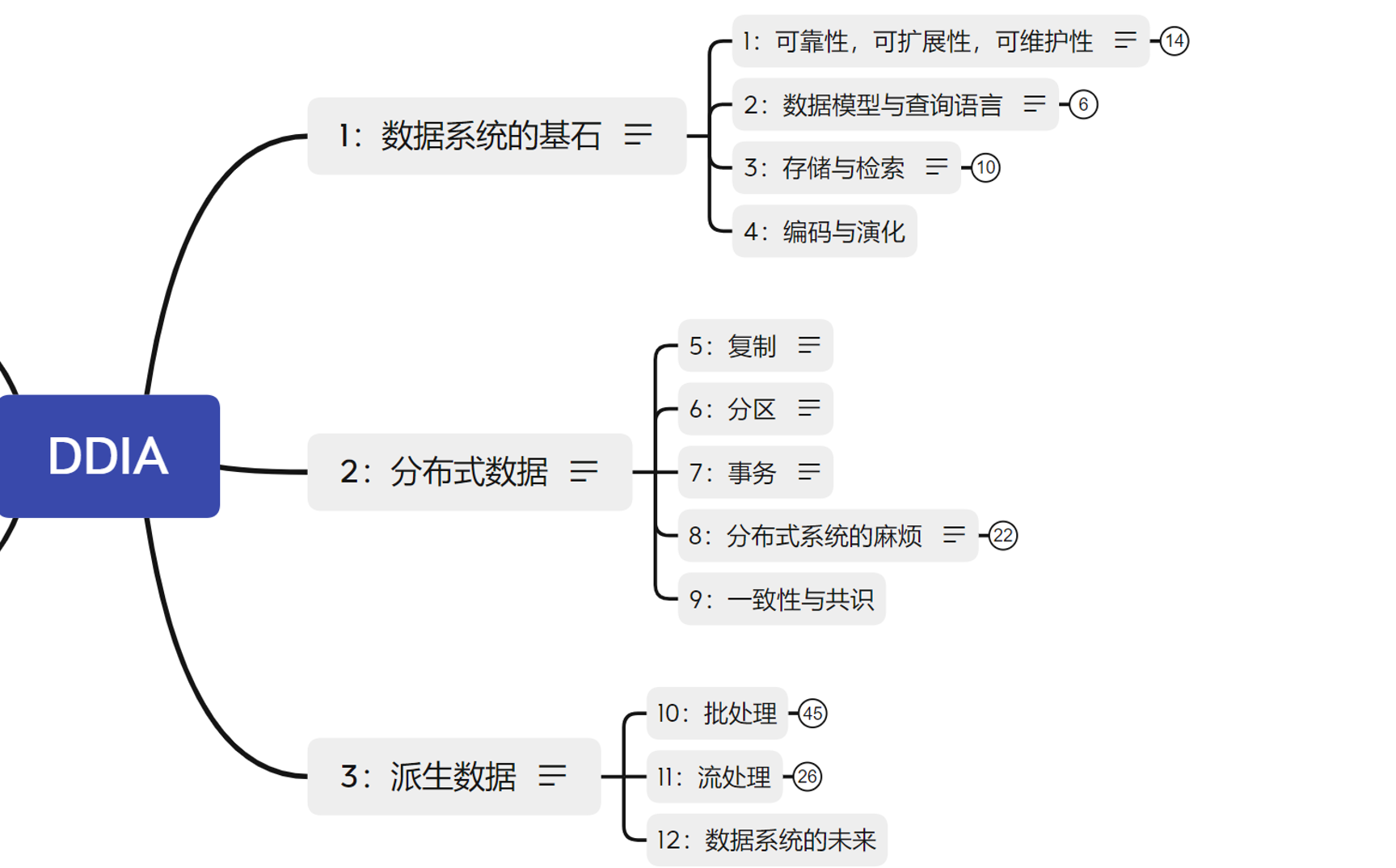
书籍结构目录
哪3部分
1⃣ 数据系统的基石
主要讲述了数据系统底层的一些概念,无论是单机上的单点数据系统,还是分布在多机器上的分布式数据系统。这个讨论的范围是 单机或者多机器,区别于第二部分仅谈论多机器上的分布式系统
1:可靠性、可扩展性、可维护性 在开发一个应用的时候,必须要满足各种功能需求才能称之为有用,除了功能需求(也就是能够实现什么功能)还需要一些非功能需求,也就是通用属性,比如说可靠性1,可扩展性2,可维护性3
1:意味着即使发生故障,系统也能正常工作
2. 意味着即使在负载增加的情况下也有保持性能的策略 ↩
3. 有许多方面,但实质上是关于工程师和运维团队的生活质量的 ↩
- 2:数据模型与查询语言 这个是从使用者的角度出发(⚠注意这个视角很重要) 。描述数据录入数据系统的格式,已及如何将存入的数据取出来。涉及关系模型,文档模型,图模型。比如说对于关系型数据库来说,数据模型 = DML(Data Manipulation Language);查询语言 = DQL(Data Query Language 一种声明式的查询语句) 。阐述了关系模型的各个挑战者挑战关系模型的霸主地位,最终落败的过程,数据模型发展至今关系模型依然王者
3:存储与检索 这个是从数据系统的角度出发,描述数据系统如何存储我们录入的数据,以及在我们需要这部分数据,存储系统如何精准、快速的定位到目标数据。这里注意区分2章节和3章节的角度
4:编码与演化 随着时间推移,数据系统由于功能的迭代,需要对初始涉及的数据模型(schema)进行更改,那么如何处理数据模型的前后兼容问题,就是这个章节要讨论的问题
2⃣ 分布式数据
本章主要讲述在多机器的分布式数据系统中,将会有多台机器参与数据的存储和检索,数据系统所面临挑战,包括
- 5:复制 : 同一份数据,多个拷贝/副本。这将为系统的可用性提供支撑
- 6:分区 : 同一份数据,分割成多块
- 7:事务 : 主要介绍 事务,ACID,隔离级别等内容,这部分内容是重点也是难点
- 8:分布式系统的麻烦 : 在极端情况下,分布式系统黑暗的诸多问题,看完这一章节,你会觉得你所处于的环境真的是太幸福了
- 9:一致性与共识 :分布式数据系统如何去实现一致性和达成共识,从而避免类似于 brain split 的问题,这一章节会讨论在构建容错分布式系统的时候使用到的 算法和协议(比如Raft、Paxos、ZAB)
3⃣ 派生数据
第一/二部分系统的考量了分布式数据库的方方面面,真实世界的大型应用程序经常需要以多种方式访问和处理数据,没有一个数据库可以同时满足所有这些不同的需求。因此应用程序通常组合使用多种组件:数据存储,索引,缓存,分析系统,等等,并实现在这些组件中移动数据的机制
该书的最后一部分,研究将多个不同数据系统(可能有着不同数据模型,并针对不同的访问模式进行优化)集成为一个协调一致的应用架构时,会遇到的问题
主要讨论衍生(派生)数据:所谓衍生数据 是以输入数据输出新的数据,输出是衍生数据(derived data)的一种形式 ,流处理和批处理都会产生衍生数据
- 10:批处理 : 有界数据的处理
- 11:流处理 : 无界数据的处理
- 12:数据系统的未来 🤣
🎈以上呢🎈,就是整本书的一个简短的概括,下面的内容就是我基于书中的内容做的一些总结,已及自己的一些启发
计算密集vs数据密集
下图是应用程序的简要分类:
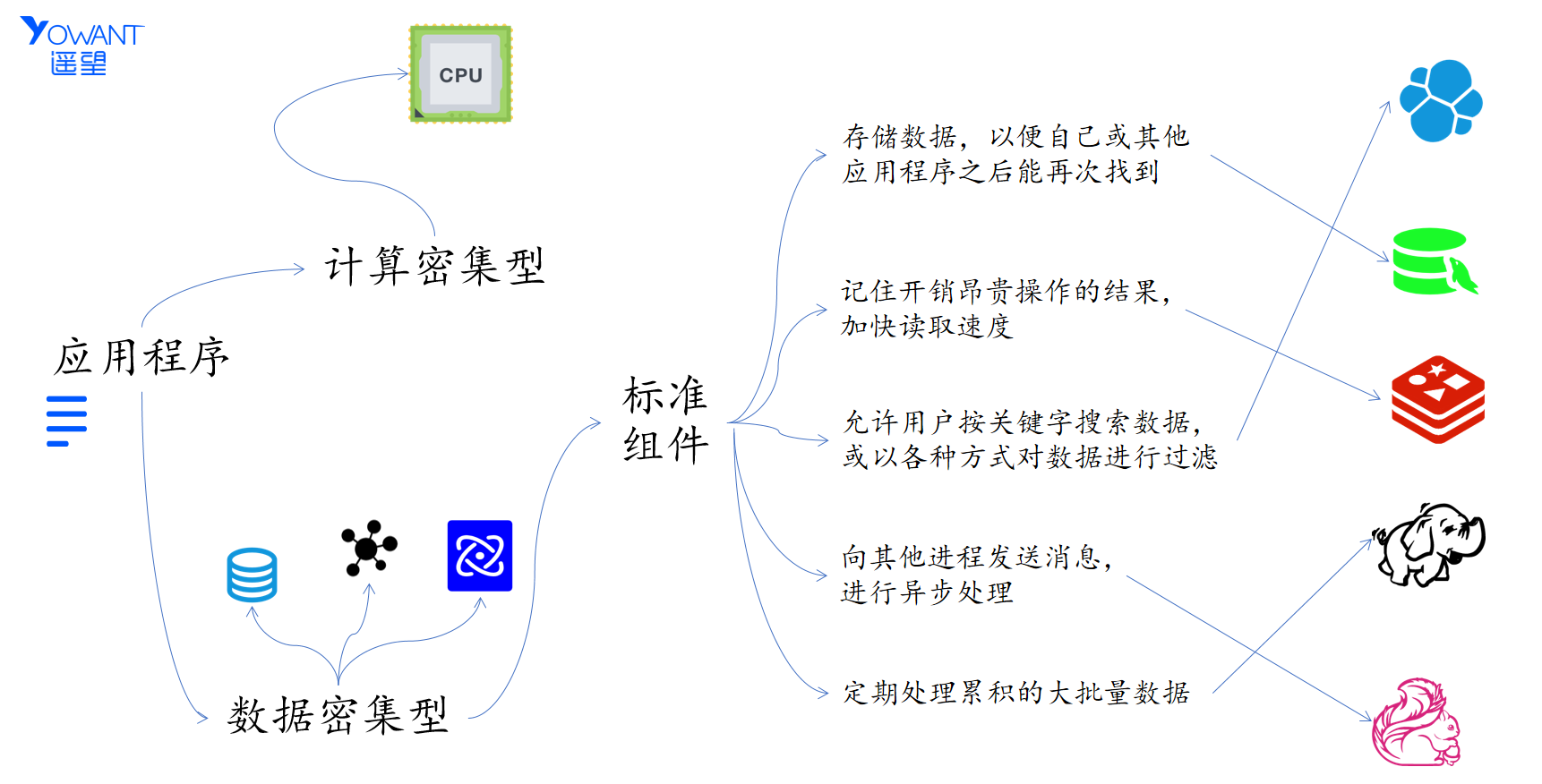
数据密集型应用和计算密集型应用的区别
🅰 首先是计算密集型应用,这类应用的瓶颈是算力,比如进行气象预测,对于这类应用我们处理的方式就是不断的提升计算机的算力,比如增加CPU的核数,增加内存等
🅱 再有就是数据密集型,这类应用的瓶颈是:
- 数据量,Volume
- 数据的复杂性,Variety
- 数据的变更速度,Velocity
对于数据密集型应用,我们通常会使用标准的组件来处理:
1⃣ 存储数据,以便自己或其他应用程序之后能再次找到(数据库 database)
2⃣ 记住开销昂贵操作的结果,加快读取速度(缓存 cache)
3⃣ 允许用户按关键字搜索数据,或以各种方式对数据进行过滤(搜索索引 search indexes)
4⃣ 向其他进程发送消息,进行异步处理(流处理 stream processing)
5⃣ 定期处理累积的大批量数据(批处理 batch processing)
如何描述负载?
可以使用负载参数(load parameters) 的数字来描述负载。参数可能是
- 每秒向Web服务器发出的请求
- 数据库中的读写比率
- 聊天室中同时活跃的用户数量
- 缓存命中率
除此之外,需要关注平均情况或者峰值情况。有写负载和读负载,如果写负载远远低于读负载,此时我们可以让写入时做更多的工作,便于我们在读取的时候做更少的工作
推特在推文写入和推文读取时,使用了两种不同的策略
如何描述性能?
批处理系统,每秒可以处理的记录数量,即吞吐量(throughput),或者在特定规模数据集上运行作业的总时间
在线系统,通常更重要的是服务的响应时间(response time),即客户端发送请求到接收响应之间的时间
一般而言,将响应时间视为一个可以测量的数值分布(distribution),而不是单个数值,比如100次请求响应时间的均值与百分位数。第95、99和99.9百分位点(缩写为p95,p99和p999),如果第95百分位点响应时间是1.5秒,则意味着100个请求中的95个响应时间快于1.5秒,而100个请求中的5个响应时间超过1.5秒
百分位点通常用于服务级别目标(SLO, service level objectives)和服务级别协议(SLA, service level agreements),即定义服务预期性能和可用性的合同,如果没达到服务目标,客户可以不付款
什么是头部阻塞?
由于服务器只能并行处理少量的事务(如受其CPU核数的限制),所以只要有少量缓慢的请求就能阻碍后续请求的处理,这种效应有时被称为 头部阻塞(head-of-line blocking),也叫做排队延迟(queueing delay),通常占了高百分位点处响应时间的很大一部分
当一个请求需要多个后端请求时,单个后端慢请求就会拖慢整个终端用户的请求,效果称为尾部延迟放大
负载参数和性能参数是讨论可扩展性的前提,可扩展性即为当负载参数增加时,如何保持良好的性能?
什么是弹性的?
如果说系统是 弹性(elastic) 的,这意味着可以在检测到负载增加时自动增加计算资源,而其他系统则是手动扩展(人工分析容量并决定向系统添加更多的机器)
第2章节-数据模型与查询语言
文档模型和关系模型的优劣势?
文档模型如JSON的优势在于结构灵活,你可以将任意的键和值添加到文档中,而在关系模型中你必须提前预设这样的字段或者进行 alter table 操作,文档模型在连接上的劣势,导致数据如果有多份,必须要存储多次,有较高的数据不一致风险。如果每次读取文档的全部或者大部分内容,查询局部性会有很大优势,而关系模型将数据分割多块的行为,不得不进行连接
关系模型一般是规范化的,能够保证数据的一致性(外键),但是其中的结构变化,是一个较耗时的操作如果表很大的话,执行 alter table & update 需要很久,此时会有锁表行为
声明式查询vs命令式查询
声明式查询告诉存储引擎:我需要Sharks类数据,而命令式查询给出找到A类数据的方法,存储引擎按照这个方法执行即可,而众多编程语言就是命令式的
1 | function getSharks() { |
SQL是一种声明式的查询语句,声明式查询不提供方法,仅指定结果的模式,接收声明的数据库可以自行选择高校的方法
1 | SELECT * FROM animals WHERE family ='Sharks'; |
MapReduce是什么
MapReduce是一个由Google推广的编程模型,它基于map(也称为collect)和reduce(也称为fold或inject)函数。它既不是一个声明式的查询语言,也不是一个完全命令式的查询API,而是处于两者之间:查询的逻辑用代码片断来表示,这些代码片段会被处理框架重复性调用
图
如果你的应用程序大多数的关系是一对多关系(树状结构化数据),或者大多数记录之间不存在关系,那么使用文档模型是合适的。关系模型可以处理多对多关系的简单情况,但是随着数据之间的连接变得更加复杂,将数据建模为图形显得更加自然
一个图由两种对象组成:顶点(vertices) 和 边(edges),典型的例子包括:社交图谱,网络图谱,公路或铁路网络
A-什么是属性图模型?
在属性图模型中,包含顶点和边,在属性图模型中,顶点和边分别包括
| 顶点(vertex) | 边(edge) |
|---|---|
| 唯一的标识符 | 唯一的标识符 |
| 一组 出边(outgoing edges) | 边的起点(tail vertex) |
| 一组 入边(ingoing edges) | 边的终点(head vertex) |
| 描述两个顶点之间关系类型的标签 | |
| 一组属性(键值对) | 一组属性(键值对) |
可以将图存储看作由两个关系表组成:一个存储顶点,另一个存储边
1 | CREATE TABLE vertices ( |
B-Cypher 属性图模型声明式查询语句
Cypher是属性图的声明式查询语言,为Neo4j图形数据库而发明
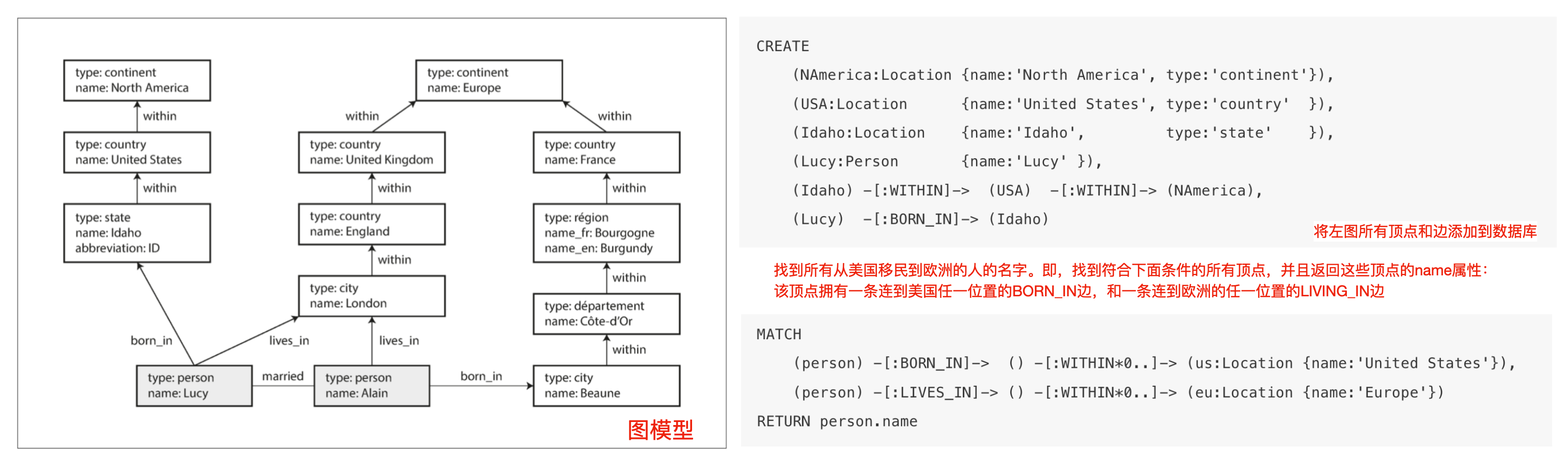
图模型&图数据写入&图数据查询
读时模式vs写时模式
读时模式(schema-on-read):数据的结构是隐含的,只有在数据被读取时才被解释,比如文档数据库
写时模式(schema-on-write):传统的关系数据库方法中,模式明确,且数据库确保所有的数据都符合其模式
读时模式类似于编程语言中的动态(运行时)类型检查,而写时模式类似于静态(编译时)类型检查,就像静态和动态类型检查的相对优点具有很大的争议性一样,数据库中模式的强制性是一个具有争议的话题,一般来说没有正确或错误的答案
总结
在历史上,数据最开始被表示为一棵大树(层次数据模型),由于不适合表示多对多的关系,发明了关系模型来解决这个问题。后来,人们发现一些应用程序也不适合采用关系模型,于是新的非关系型“NoSQL”数据
- 文档数据库的应用场景是:数据通常是自我包含的,而且文档之间的关系非常稀少。
- 图形数据库用于相反的场景:任意事物都可能与任何事物相关联。
这三种模型(文档,关系和图形)在今天都被广泛使用
第3章节-存储与检索
存储与检索的内容,即:数据库在最基础的层次上完成的2件事情:
🅰 当你把数据交付给它的时候,它如何将数据存储起来
🅱 当你向数据库索要数据时,它如何将数据返回给你
由于事务性负载和分析性负载的存储引擎之间存在着很大的差异,这两类的存储引擎我们分开来描述
在事务处理方面:
- 日志结构存储引擎 ;从最简单的数据库实现append-log(无索引日志)到 LSM(日志结构合并树) 树的演化历程
- 面向页面的存储引擎 ,典型的比如B-Tree
在分析性存储引擎方面,我们谈谈
- 数据仓库
- 星型模型&雪花模型
- 列存储
无索引日志
我们来看下 世界上最简单的数据库 是如何实现的
- 插入操作(
db_set) - 更新操作(
db_set) - 查询操作(
db_get)

无索引日志 & 最简单的数据库

康熙字段VS新华字典
当我们还是一个小学生的时候,可能面临过类似的问题,假设说现在有2个小学生,忘记了囧字怎么写,想要用新华字典查询一下:
小明同学使用的是一本没有目录的字典(比如说康熙字典)
小红同学 使用的是一本有目录的字典(现代新华字典)
那么谁最后能更快的获知
jiong字的写法呢?直觉告诉我们小红同学有较大的概率最快获取到joing字的写法
现代字典的特征就是都会有一个目录,这个目录是在原始数据之外维护的额外的数据,正是由于目录的存在,使得小红同学能够更快的获取到目标数据。其实这个目录,其实就相当于英文中的 index , 而 index英译就是索引,至此我们可以得到一个结论:
索引 是在原始数据之外维护的额外的数据,索引 可以加速数据访问
🎈Post Script🎈
由于需要在原始数据之外额外维护一份数据,这就无形增加了空间复杂度,在计算机领域中,时间和空间就像鱼和熊掌一样,不可兼得,降低时间复杂度的方式就用空间换取时间; 可以说这个问题在计算机领域是一个绕不开的话题,如何去提升查找效率这个问题的另外一种问法是:给我一个更低的时间复杂度的实现,那么常见的比 $O(n)$ 还低的时间复杂度就是 $O(1)$, $O (log_n)$ 两个,$O(1)$ 的时间复杂度,我们很容易就会想到哈希表,因为哈希表的时间复杂度默认是 $O(1)$,接下来我们尝试构建哈希索引来提升查询效率
内存中构建hash索引
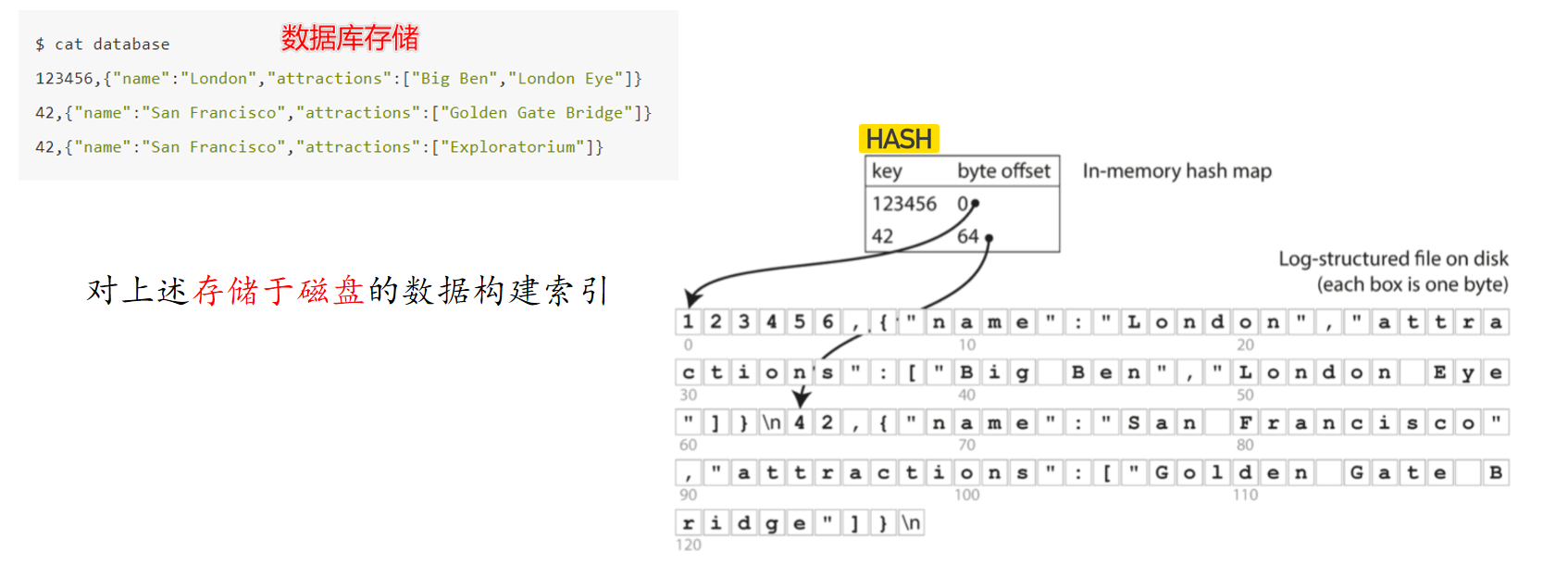
为日志构建哈希索引
那么对于存储于磁盘中的数据,我们在内存中维护一个HashMap,维护key和value 的偏移量,这样一来,我们就能够迅速的定位到目标数据,比如我们想要找到 key = 42 的数据,通过查询内存中的HashMap表,获得偏移量64 ,所以可以直接定位到数据,而不在需要从头开始遍历
随着我们不断的在文件末尾追加文件,磁盘中的单个文件也会越来越大,甚至单个文件可能吃掉整个磁盘的存储。所以,如何用有限的存储存储更多的数据? 即,如何避免磁盘的空间的消耗?
分段存储&压缩&分段合并 & hash索引的局限性
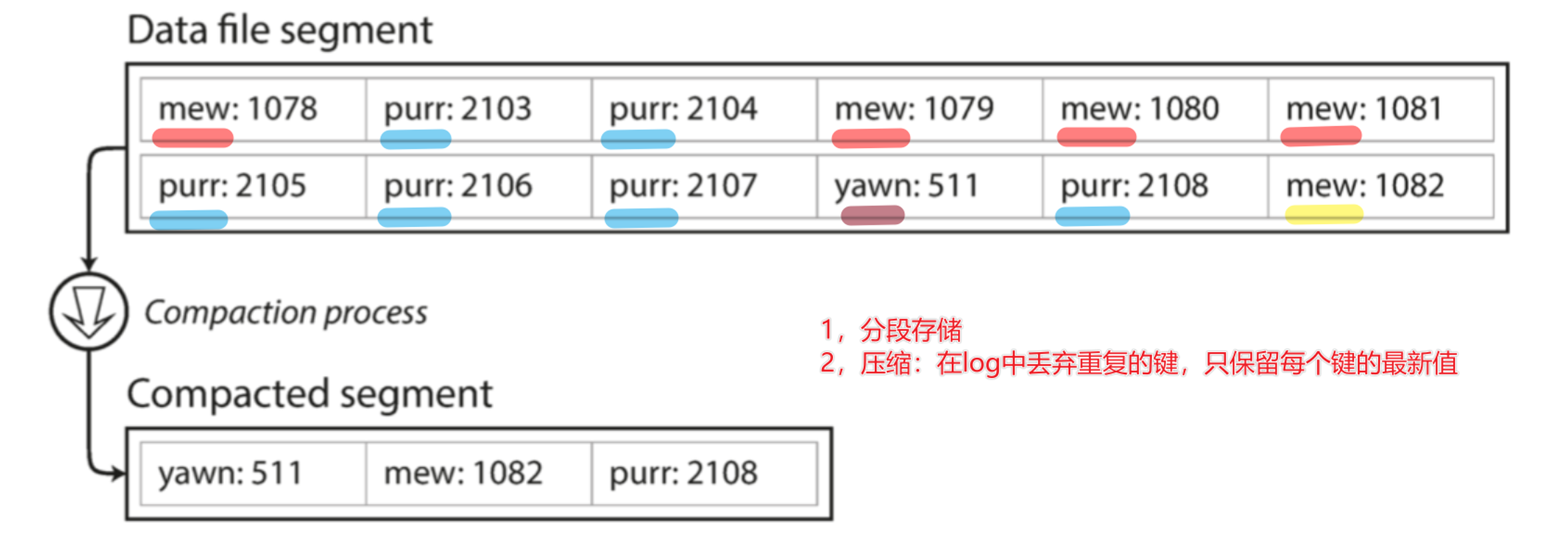
日志分段 & 分段日志压缩
我们解决的方案是:
分段存储:也就是说当追加文件的
size(通常是几兆字节) 达到了一定的阈值之后,我们重新写入新的文件(每个段维护自己的索引)压缩:丢弃重复的键,保留每个键的最新值
如上图中原本12个键 压缩之后之后3个键,整个文件的size降低。如何进一步改进?
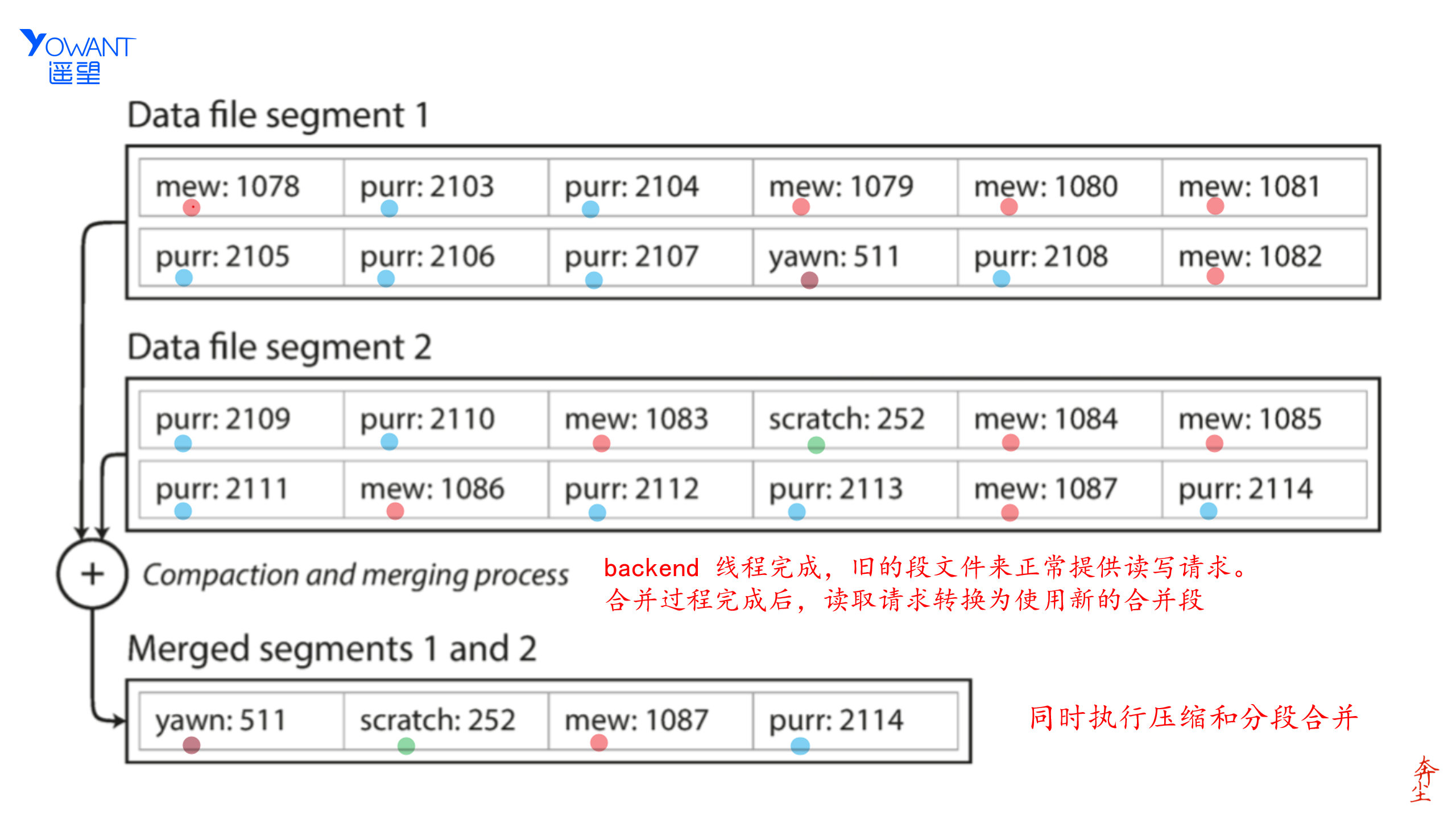
日志分段 & 分段日志压缩 & 压缩日志合并
在执行压缩的同时,可以将压缩之后的段合并。如 Data file segment 1 和 Data file Segment 2 在压缩了之后,进行了一个合并操作,得到了 Merged Segment(比如mew 这个键压缩合并的过程)。压缩和合并对用户是没有感知的,由后台进程完成,在合并的时候由旧的段文件提供读写请求,在合并完成之后,读写请求转化为新的合并后的段
那么由于hash表本身的特性,也会导致我们构建的哈希索引有一定的局限性,比如:
🅰 哈希表是存在于内存中的
🅱 范围查询是软肋
那么如何突破哈希表的局限性,寻找更好的索引结构?
SSTable 排序字符串表
这个问题的答案是:排序字符串表,也就是SSTable5, 也就是:在段文件中,对键值对的序列排序

SStable
比如上图中,对于已经排好序段文件1,段文件2 ,段文件3 ,进行压缩和合并,而且,在合并之后,仍然需要保证合并之后的段文件有序,所以我们需要一个合适的排序算法:那么这个排序算法是什么呢? 是冯诺依曼发明的归并排序算法;merge sort 的优势就在于:内存在小于被排序文件大小的时候,仍然可以将排序完成
5:SSTable : Sort String Table ,排序字符串表,对每个段文件中的键进行排序
使用SSTable可以有效的突破内存限制和解决范围查询的问题。如下图中我们查找,handiwork 的过程,可以发现不是在内存中保存所有键的索引,由于SSTable维护了顺序关系,我们的索引以稀疏索引的方式存在于内存中。同时,可以支持范围查询
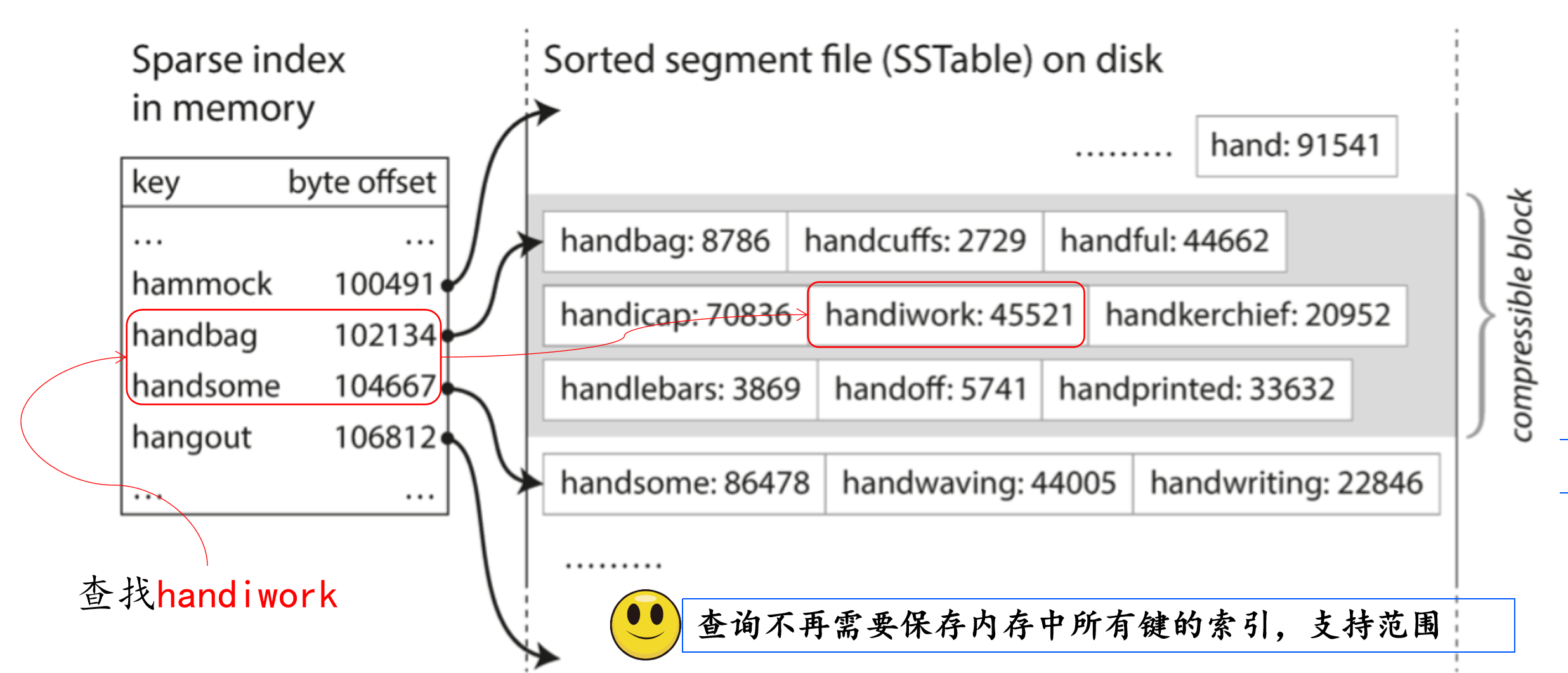
稀疏索引,比如每几千个字节一个键
LSM 日志结构合并树
在前面的讲述中,我们默认了落盘段文件是有序的,在落盘写入段文件之前,如何按键排序?考虑到效率问题,最初的的写入一定是在内存中的,到达一定的时间阈值或者是内存阈值的时候,在进行落盘形成 SSTable,那么内存中选择什么样的数据结构?
1⃣ 内存表,为什么是AVL-Tree ?
- 首先平衡二叉树本身就是二叉搜索树,而二叉搜索树中序遍历就是顺序结构,可以直接落盘形成SSTable
- 由于平衡特性,可以保持树的结构,而不是退化成链表,使得查询的时间复杂度维持在 $O(logN)$, 而且对于新加入的数据,平衡二叉树通过左旋,或者右旋的方式保持平衡性
2⃣ 落盘,也就是平衡二叉树的中序遍历方式落盘
3⃣ 读取请求,先请求内存,然后查询磁盘段
4⃣ 压缩和合并: 后台压缩合并段文件,并丢弃覆盖/删除旧值
5⃣ 防止数据库崩溃(保存在AVL-Tree,但是未落盘到SStable):磁盘保留一份单独的日志,每个写入都追加到磁盘上,防止数据库崩溃,内存数据丢失

那么使用这种LSM结构的组件有哪些
Cassandra6、Bigtable、HBase、Elasticsearch、Solr7、Hologres33
6. 卡桑德拉,Apache Cassandra是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于改善电子邮件系统的搜索性能的简单格式数据,集Google BigTable的数据模型与Amazon Dynamo的完全分布式架构于一身 ↩7. 和ES一样是一个企业级的搜索索引 ↩33:Hologres存储引擎: https://developer.aliyun.com/article/779284?spm=a2c4g.11186623.0.0.11cf49fc9XL2Nw&groupCode=hologres
这种先内存排序,再落盘排序的结构,就是LSM(Log-Structure Merge Tree 日志结构合并树)结构,LSM结构和B+-Tree相比,减少了随机IO,极大的提高的写性能
面向页存储引擎
接下来我们介绍另外一种存储引擎:面向页面的存储引擎,比如B 树,B树会将数据库分解为固定大小的块或者是页面34,传统大小为4K而且一次只能读取或者写入一个页面,和LSM对比一下

B树和LSM比对
34. 固定大小的块或者页面:如果读者注意到过SQL引擎的执行计划的话,一般会有一个类似seq_page_cost(postgresql叫这个)的参数描述的就是每次Planner抓取一个数据页的成本(cost), the planner’s estimate of the cost of a disk page fetch that is part of a series of sequential fetches ↩
下图展示了面向页面的存储引擎是如何查询数据的
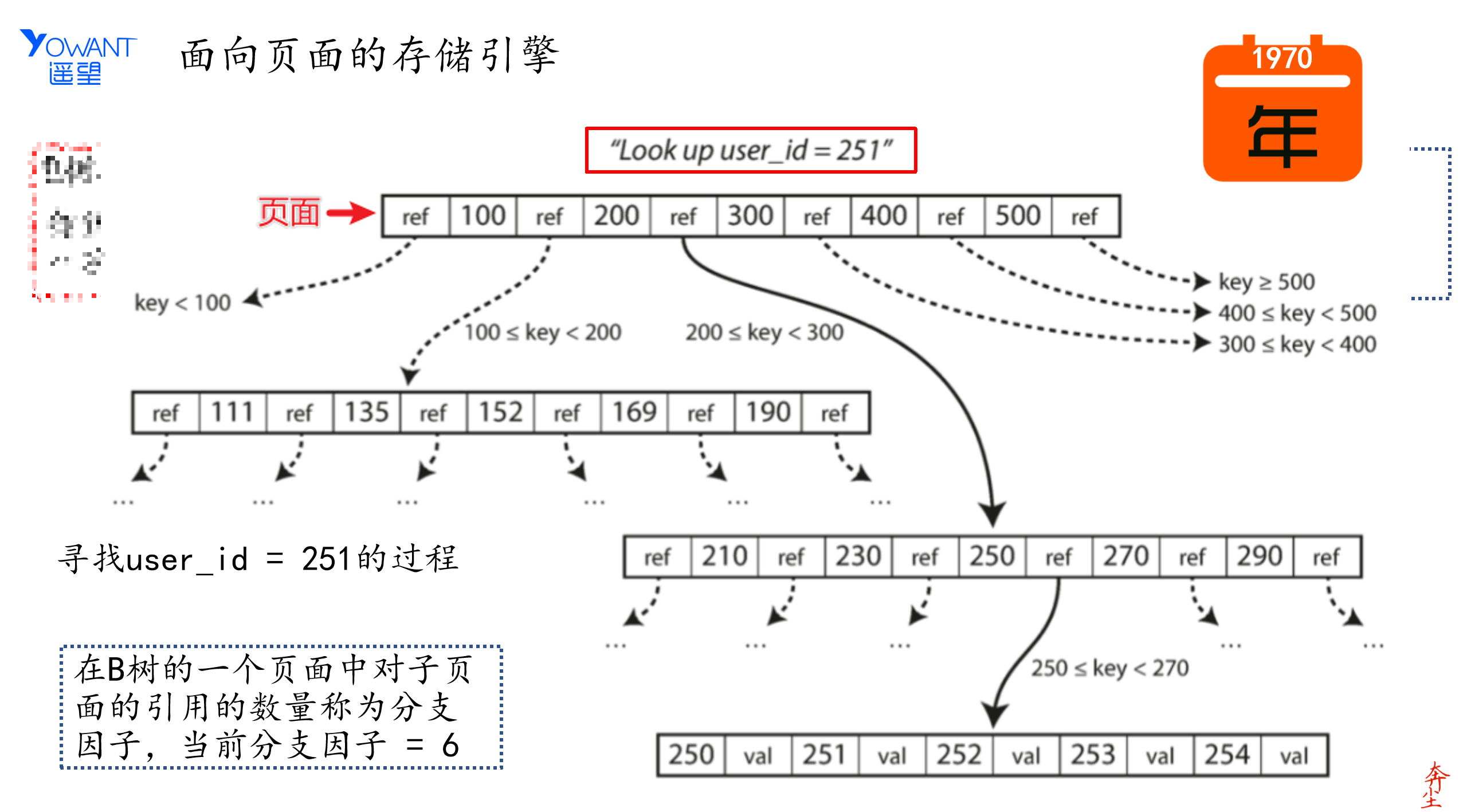
面向页面的存储引擎是如何查询数据的
分支因子:在B树中一个页面中对子页面的引用数量。伴随着上世纪70年代关系型数据库的发展至今,面向页面的存储引擎发展至今已经非常成熟了
向页面添加元素
如何向B树中增加一个数据,如下图:
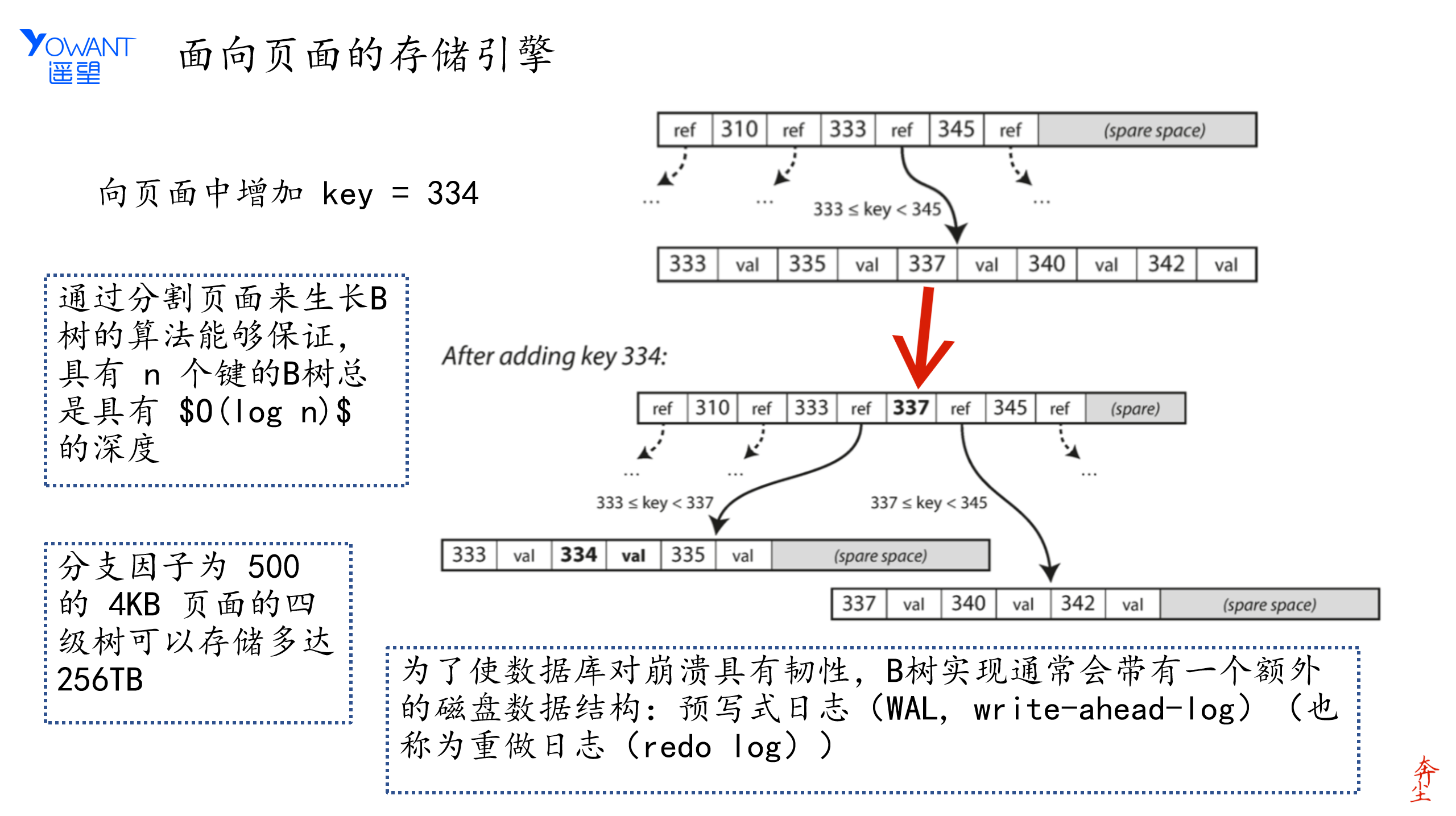
如何向B树中增加一个数据
WAL即在数据写数据页之前,先记录到”小黑板”~WAL~上,对于一个更新操作来说,如果每次更新都需要立刻写磁盘,存储引擎需要找到被更新的记录,然后更新,这个先定位再更新的机制必然有一定的成本(查找成本+IO成本),如果引擎会将记录写到 文件 里,并且更新内存,在适当(系统比较空)的时候,将操作记录刷写到磁盘, 如此便可以提升更新效率。事实上MySQL的InnDB 引擎就是这么做的
比对LSM树 和 B树
最后我们来一起对比一下LSM树和B树,也即面向日志的存储引擎和面向B树的存储引擎的优劣势
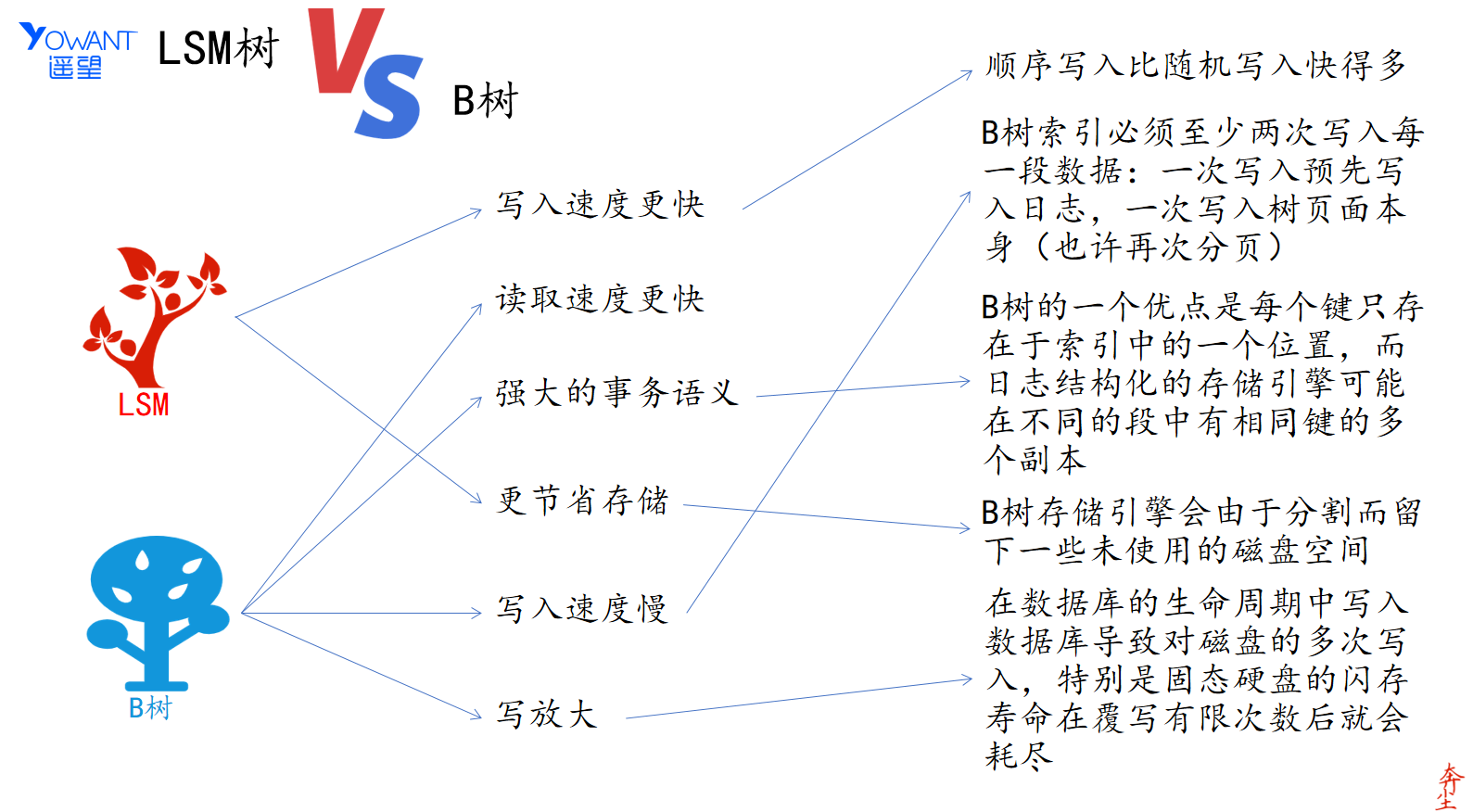
比对LSM树 和 B树
OLTP&OLAP 和 数据仓库
数据库在历史中主要为两种系统提供支持
🅰 在线事务处理系统,即 OLTP
🅱 在线分析系统,即 OLAP
下表中对比了两者之间的区别,
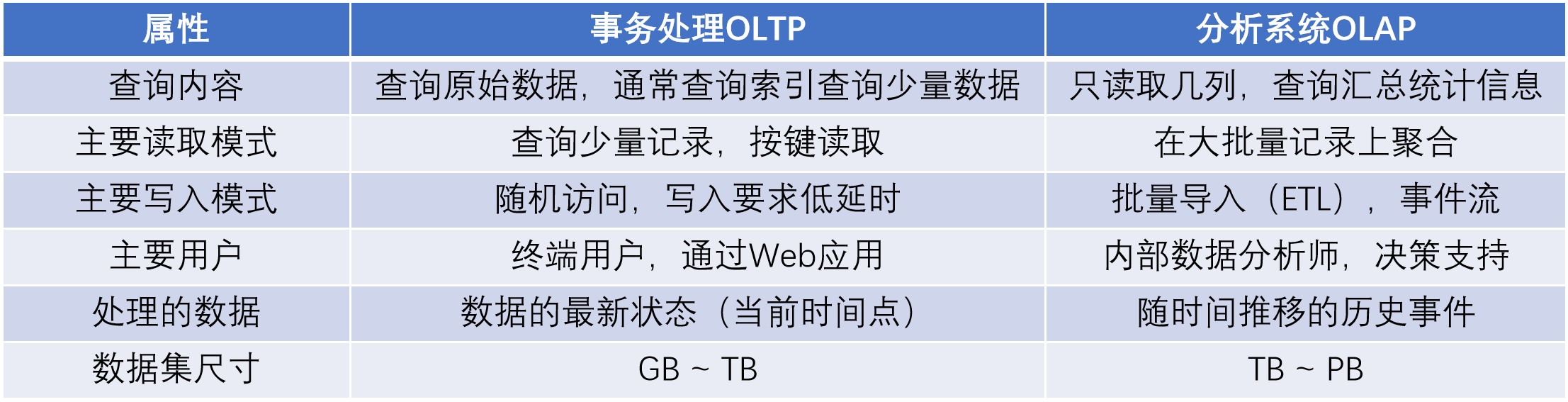
OLTP 对比 OLAP
起初的数据库,能够同时应对以上两种查询的情况,无论是OLTP类型的查询,还是OLAP类型的查询,单一的数据库的表现的都很好,也就是说:也就是说两者是一家的。 OLAP通常会要求 高可用与低延迟,为了保证业务系统的稳定运行,所以DBA会密切关注他们的OLTP数据库,他们通常不愿意让业务分析人员在OLTP数据库上运行临时分析查询,因为这些查询通常开销巨大,会扫描大部分数据集,这会损害同时执行的事务的性能。可以见得,OALP和OLTP 这对亲兄弟发生了矛盾,矛盾会最佳解决方案就是分家
在20世纪80年代末和90年代初期,渐渐地很多公司有停止使用OLTP系统进行分析,而是在单独的数据库上运行分析。这个单独的数据库被称为数据仓库(data warehouse)。因为最初的数据仓库是从关系型数据库中独立出来,只存储关系数据,而且是面向数据分析,BI(商业智能)的,只是到了后来随着大数据时代的到来,数据仓库才慢慢变的越来越像数据湖8 (就是各种数据都跑往数据仓库里面塞)
8. 数据湖:是指使用大型二进制对象或文件这样的自然格式储存数据的系统[1] ,数据湖可以包括关系数据库的结构化数据(行与列)、半结构化的数据(CSV,日志,XML, JSON),非结构化数据 (电子邮件、文件、PDF)和 二进制数据(图像、音频、视频) ↩数据沼泽:数据沼泽 是一个劣化的数据湖,用户无法访问,或是没什么价值
又或者说,数据湖是下一代数据仓库,从OLTP数据库中提取数据,转换成适合分析的模式,清理并加载到数据仓库中,因此数据仓库包含公司各种OLTP系统中所有的只读数据副本。下图是一个简要的示意图:
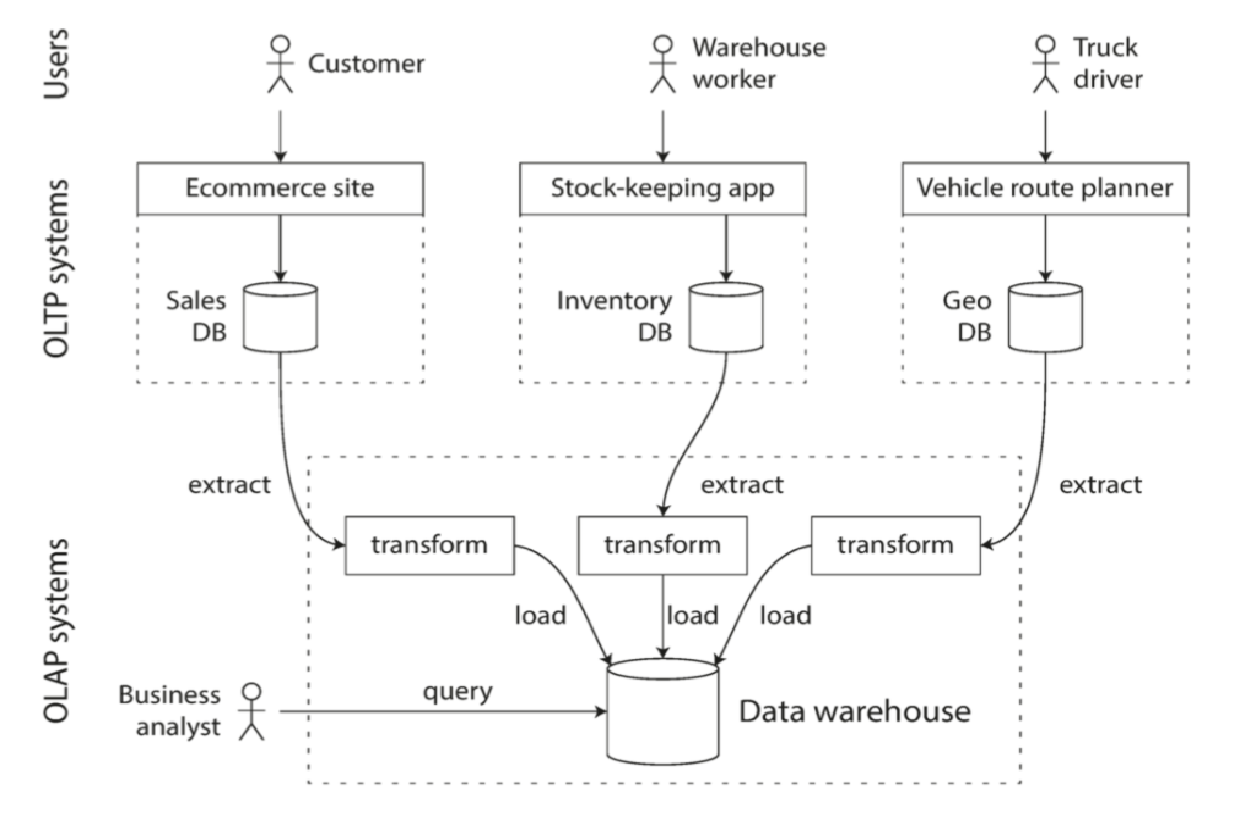
ETL过程
数据仓库系统组件
我们来看一些比较出名的商业数据仓库系统,尽管他们是冠以出名的商业数据仓库系统,但是其中”商业”两个字可能是太贵,导致大多数从事数据仓库相关工作的人,其实并不知道:

- SQL - Server 使用两套不同的存储和查询引擎来应对OALP和OLTP环境
- Teradata 天睿
- Vertica 维蒂卡
- SAP HANA SAP 汉那
- ParAccel 帕加速
相对而言,我们更喜欢免费的开源产品,下面是一些SQL-on-Hadoop 项目:
Hive-SQL、Spark-SQL、Flink-SQL、Presto、Druid、Kylin、Impala
雪花模型
在OLTP系统中,可用的数据模型很丰富,比如大类上分为
🅰 关系模型
🅱 新的非关系模型,No-SQL模型
- 文档数据库模型
- 图形数据库模型
相对于OATP系统来说,OLAP系统的数据模型多样性就少的多,数据仓库大多使用一样的公式化模型:星型模式|星型模型(也叫维度建模) 如下图:
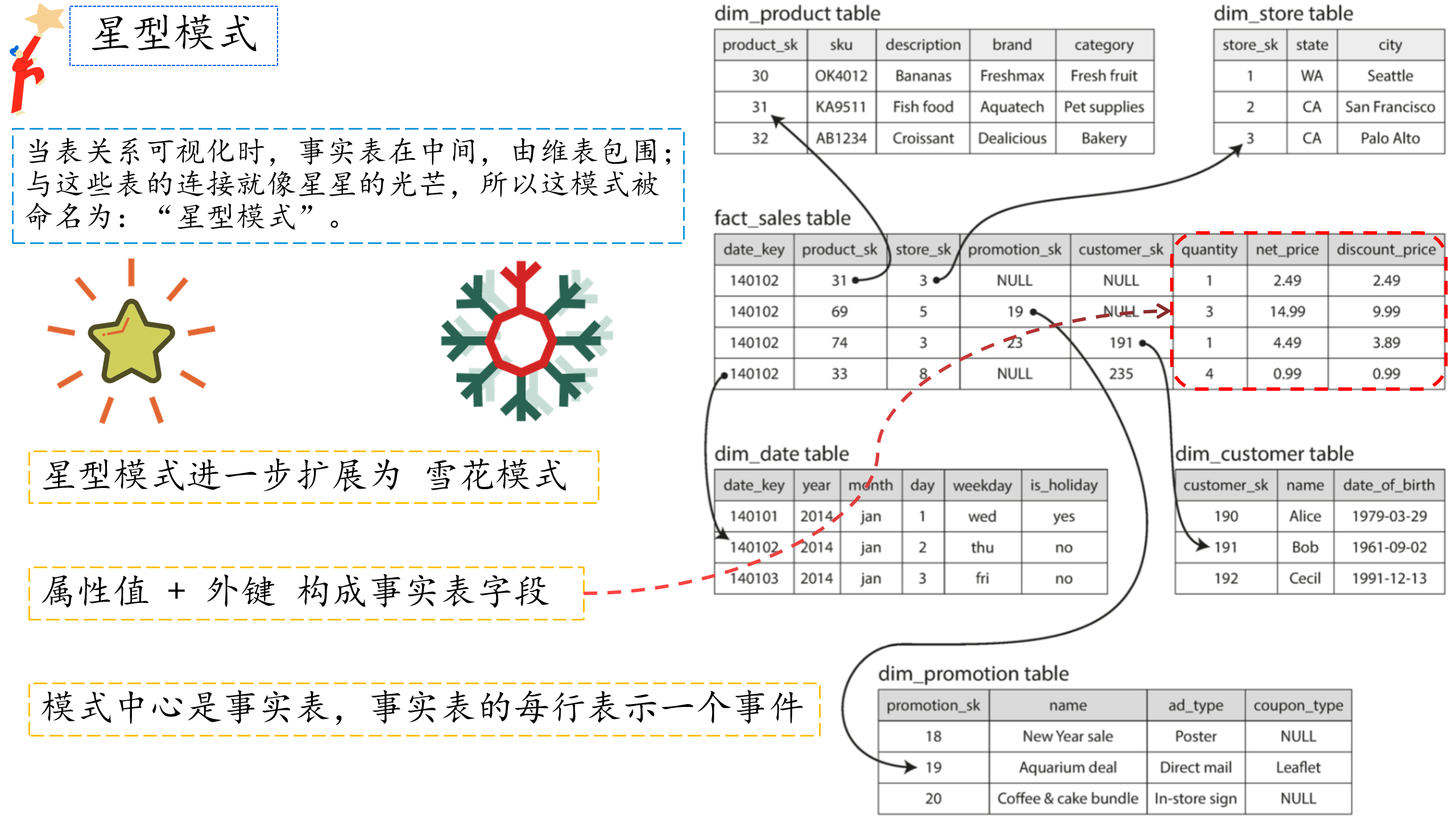
星型模式示意图
1⃣ 模式的中心是一个所谓的事实表,事实表的每一行代表在特定时间发生的事件(这里,每一行代表客户购买的产品)
2⃣ 事实表中的一些列是属性,例如产品销售的价格和从供应商那里购买的成本(允许计算利润余额),通常是数字等可统计指标
3⃣ 事实表中的其他列是对其他表(称为维表)的外键引用,由于事实表中的每一行都表示一个事件,因此这些维度代表事件的发生地点,时间,方式和原因
4⃣ 事实表格有100列以上,有时甚至有数百列,快手宽表列长达1000+列
5⃣ 星型模型进一步的扩展是雪花模型,也就是基于维度表进一步拆分
当表关系可视化时,事实表在中间,由维表包围;与这些表的连接就像星星的光芒,所以这模式被命名为:“星型模式”
列式存储
在前面的存储结构中,我们介绍了
🅰 基于日志的存储:日志结构学派
🅱 基于页面的存储:就地更新学派
然而,典型的数据仓库查询一次只访问较少的列,如果使用行存储的话,面向行的存储引擎仍然需要将所有这些行(每个包含超过100个属性)从磁盘加载到内存中,解析它们,并过滤掉那些不符合要求的条件。这可能需要很长时间。面向列的存储背后的想法很简单:不要将所有来自一行的值存储在一起,而是将来自每一列的所有值存储在一起。如下图
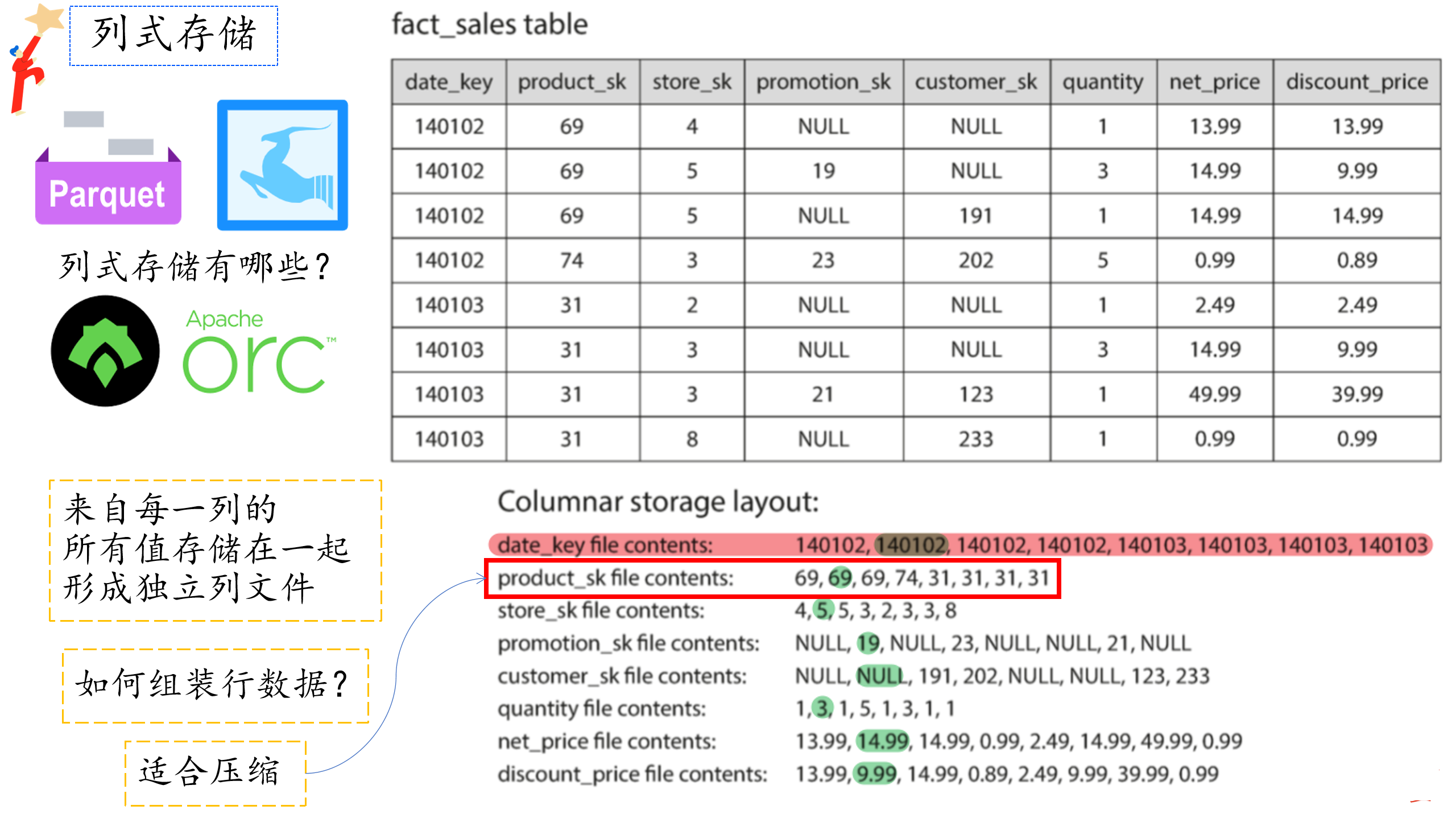
列式存储示意图
可以观察到红色框选出来的值序列,他们是重复数据,而重复数据是压缩的好兆头。我们根据列中的数据,可以使用不同的压缩技术来进一步降低对磁盘吞吐量的需求,在数据仓库中特别有效的一种技术是位图编码(类似哈夫曼编码),如下图:
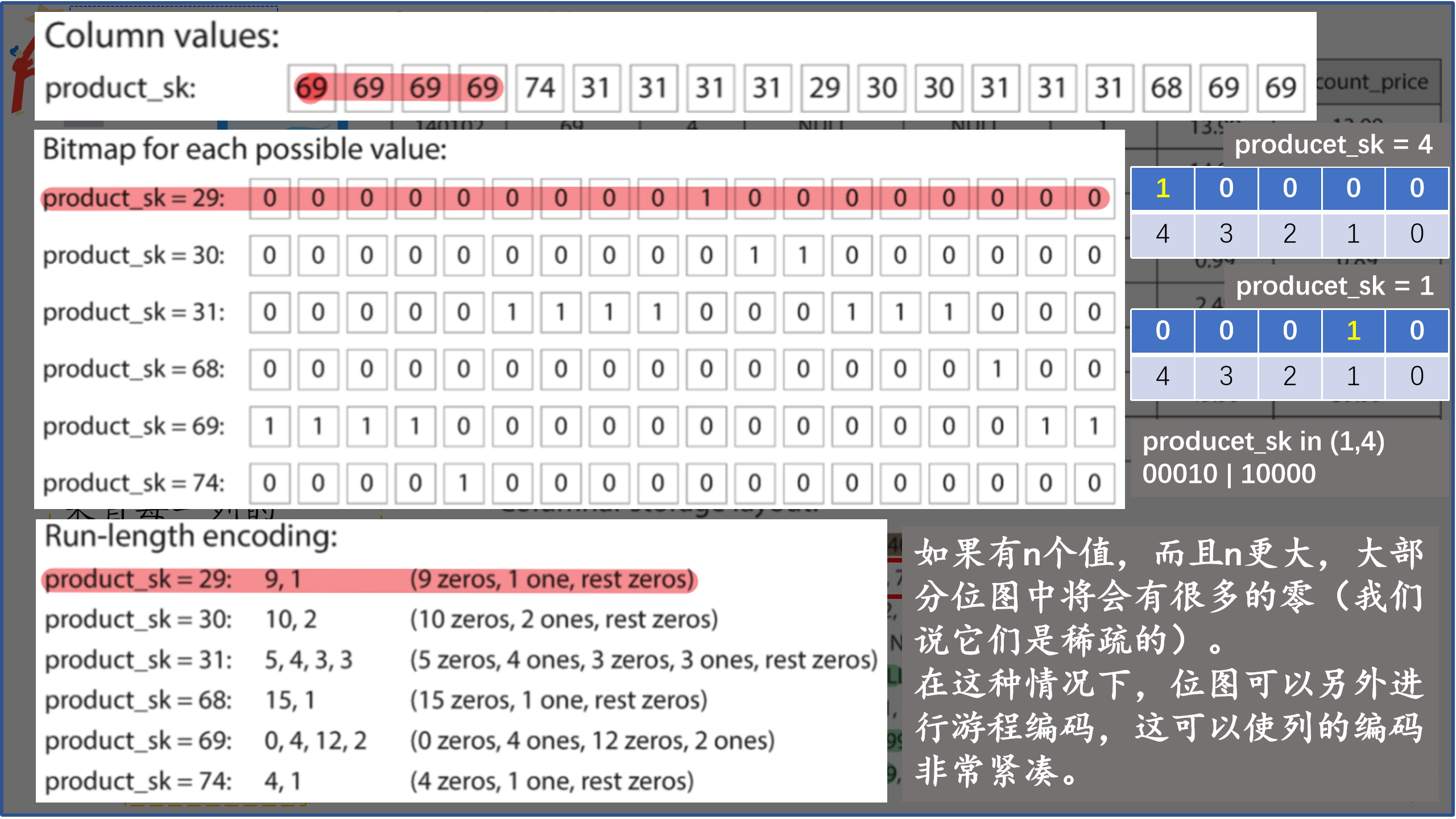
位图编码和压缩
1 | in () -- 对应着位图的 或 |
比如hive支持的存储格式包括textfile,parquet, rcfile,orc, 其中orc是rcfile的优化版(Optimize Rcfile,Rcfile基于Lazy Decompression),相较于rcfile有更好的表现,列存和压缩通常会结合,压缩比ORC(ZLIB压缩) > Parquet (Uncompress即默认不压缩)> textFile(textfile不压缩),注意点是压缩在有效降低IO的同时会提升CPU的消耗
列存储中的排列顺序也非常有意义。需要注意的是:即使按列存储数据,也需要一次对整行进行排序,一般对最常见的查询字段做为第一排序的列,第二列可以确定第一列中具有相同值的任何行的排序顺序,这将加快查询速度。同时,排序顺序可以帮助压缩列,第一个排序键的压缩效果最强,一个简单的运行长度编码(比如位图)可以将该列压缩到几千字节 —— 即使表中有数十亿行(不同的值很少,基数少)
写入列存储的困难
如果你想在列存排序表的中间插入一行,你很可能不得不重写所有的列文件。由于行由列中的位置标识,因此插入必须始终更新所有列(这大概就是Hive仅仅支持 overwrite操作的缘故)
另外的解决方案是,LSM树的这种结构,所有的写操作首先进入一个内存中的存储,在这里它们被添加到一个已排序的结构中,并准备写入磁盘。内存中的存储是面向行还是列的,这并不重要。当已经积累了足够的写入数据时,它们将与磁盘上的列文件合并,并批量写入新文件
什么是物化视图?
据仓库查询通常涉及一个聚合函数,如SQL中的COUNT,SUM,AVG,MIN或MAX。如果相同的聚合被许多不同的查询使用,那么每次都可以通过原始数据来处理。为什么不缓存一些查询使用最频繁的计数或总和?创建这种缓存的一种方式是物化视图。物化视图的常见特例称为数据立方体或OLAP立方
物化视图 和 虚拟视图的区别?
不同的是,物化视图是查询结果的实际副本,写入磁盘,而虚拟视图只是写入查询的捷径。从虚拟视图读取时,SQL引擎会将其展开到视图的底层查询中,然后处理展开的查询
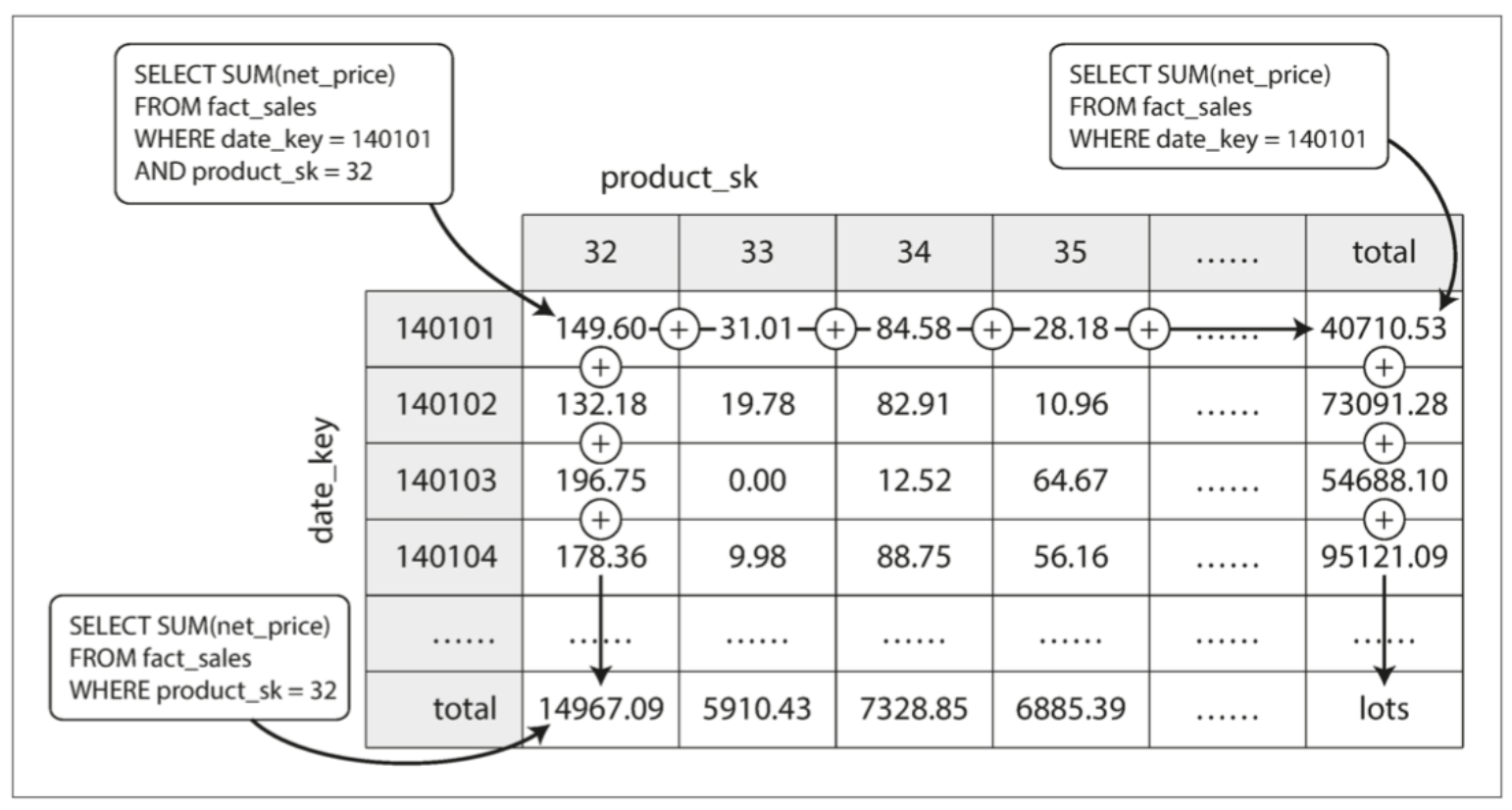
数据立方的两个维度,通过求和聚合
第四章节-编码和演化
什么是可演化性?
能灵活适应变化的系统, 修改数据系统并使其适应不断变化需求的容易程度,是与简单性和抽象性密切相关的:简单易懂的系统通常比复杂系统更容易修改
向后兼容,向前兼容
向后兼容(backward compatibility):新代码可以读旧数据
向前兼容(forward compatibility):旧代码可以读新数据
编码数据的格式有哪些?
在内存中,数据保存在对象,结构体,列表,数组,哈希表,树等中。 这些数据结构针对CPU的高效访问和操作进行了优化(通常使用指针)
如果要将数据写入文件,或通过网络发送,则必须将其编码为某种自包含的字节序列(例如,JSON文档)
从内存中表示到字节序列的转换称为编码(也称为序列化(serialization)或编组(marshalling)),反过来称为解码(Decoding)(解析(Parsing),反序列化(deserialization),反编组( unmarshalling))
编码过程也成为序列化Serialization,其中事务的隔离级别中也出现了该词,请区分2者
在一些编程语言中,都内建了将内存对象编码为字节序列的支持,Java有
java.io.Serializable,Python有pickle
文本编码和二进制编码
| 比对方面 | 文本编码 | 二进制编码 |
|---|---|---|
| 可读性 | 人类易读 | 人类不可读 |
| 数据类型 | 表示文本字符,如字母、数字、符号 | 表示各种类型的数据,包括整数、浮点数、图像、音频、程序指令等 |
| 编码方式 | 采用字符集(如ASCII、UTF-8、ISO-8859-1等)来将字符映射到数字或二进制,每个字符都有一个唯一的编码值 | 将数据直接表示为由 0 和 1 组成的二进制序列的方式。它不需要字符集 |
| 应用领域 | 处理文本数据,如文档、网页、电子邮件等 | 用于计算机内部数据表示、存储和通信,包括整数、浮点数、图像、音频、视频等。它处理的是更底层的数据表示 |
1 | // 二进制编码示例,删除了空格换行后,81个字节 |
接下来我们使用不同的二进制编码组件/库对上述的JSON文档进行编码
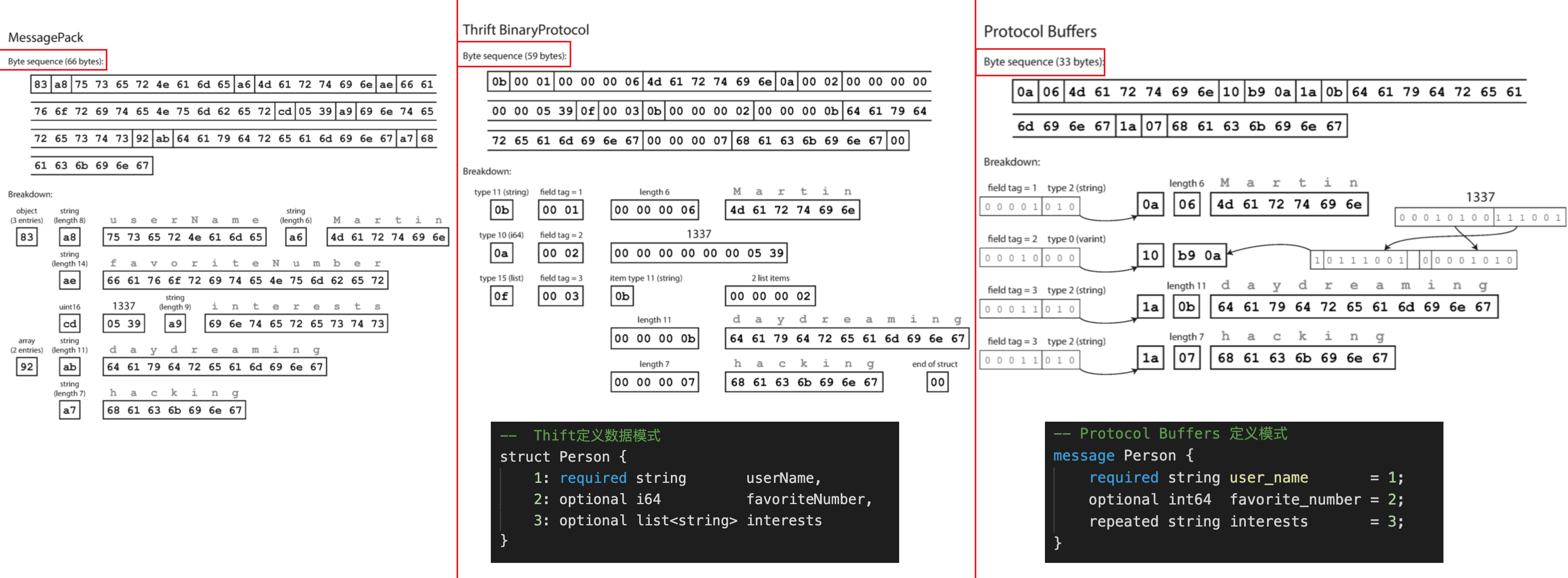
使用不同的二进制组件编码同一个JSON文档
Avro也使用模式来指定正在编码的数据的结构, 它有两种模式语言:一种(Avro IDL)用于人工编辑,一种(基于JSON),更易于机器读取
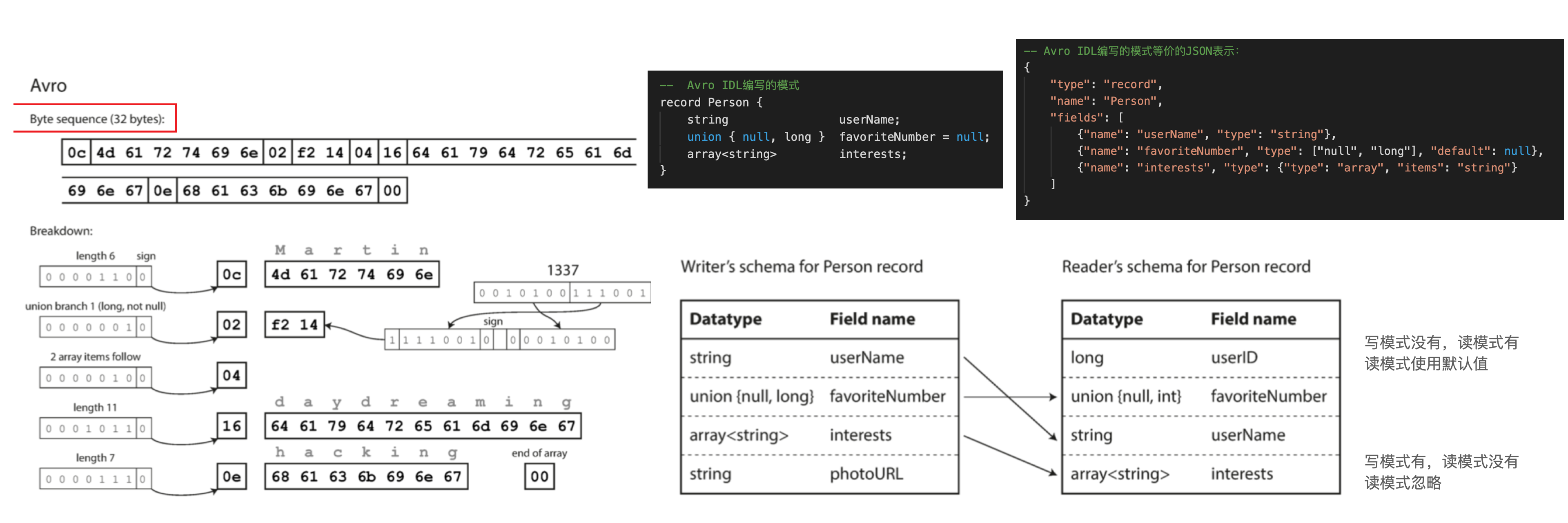
Avro 二进制编码 & Avro Reader 解决读写模式的差异
数据流的类型
如果要将某些数据发送到不共享内存的另一个进程,例如,通过网络发送数据或将其写入文件,就需要将它编码为一个字节序列
数据在流程之间流动的一些最常见的方式:
- 通过数据库:写入编码,读取解码
- 通过服务调用:REST和RPC
- 通过异步消息传递:消息队列
A-Web服务
有两种流行的Web服务方法:REST和SOAP
将大型应用程序按照功能区域分解为较小的服务,一个服务请求另外一个服务的功能或者数据,这种构建应用程序的方式传统上被称为 面向服务的体系结构(service-oriented architecture,SOA) ,也称之为 微服务架构
REST是一个基于HTTP原则的设计哲学。它强调简单的数据格式,使用URL来标识资源,并使用HTTP功能进行缓存控制,身份验证和内容类型协商。与SOAP相比,REST已经越来越受欢迎,至少在跨组织服务集成的背景下【36】,并经常与微服务相关[31]。根据REST原则设计的API称为RESTful。
B-RPC
RPC是一种协议无关的通信方式,通常使用二进制协议(如Protobuf、Thrift)或文本协议(如XML-RPC、JSON-RPC)来传输数据。它允许客户端调用远程服务器上的函数,就像本地函数一样。RPC通常是无状态的,通常使用二进制格式以提高效率
RESTful:RESTful是基于HTTP协议的通信方式,使用HTTP动词(GET、POST、PUT、DELETE等)来执行操作,并使用URL来定位资源。它使用标准的HTTP状态码来表示操作的结果。RESTful通常使用文本格式,如JSON或XML,以便数据可以被轻松解析和理解
RPC框架的主要重点在于同一组织拥有的服务之间的请求,通常在同一数据中心内
第5章节-复制
接下来是第5章的内容,这章节的内容主要是复制,所谓复制就是同一份数据保留多个副本。 复制数据的原因呢?
1⃣ 使得数据与用户在地理上接近(减少延迟)
2⃣ 即使系统的一部分出现故障,系统也能继续工作(提高可用性)
3⃣ 扩展可以接受读请求的机器数量(提高读取吞吐量)
本章主要讨论三种变更复制算法(区别于复制方法/策略):单主复制、多主复制、无主复制。当存在多个副本时,会不可避免的出现一个问题:如何确保所有数据都落在了所有的副本上?所以,复本机制真正的麻烦在于如何处理复制数据的变更 。我们来看一个非常普遍且常用解决方案:单主复制
单主复制
来具体看一个场景,更换新的用户头像的实例:

单主复制
总结一下单主复制符合以下的特点:
1⃣ 多个副本中只有一个设置为leader,其他是flower
2⃣ leader接受读请求和写请求,follower只接受读请求
3⃣ follower从leader拉取日志,更新本地数据库副本
这种复制模式是很多关系型数据库内置的功能,比如PostgreSQL(9.0之后),MySQL,SQL Server,文档型数据库 MongoDB。基于领导者的复制不局限于数据库,像一些高可用的分布式MQ也在用,比如Kafka、RabbitMQ
关于主从和主备,主从中,“从”是向外提供服务的,而主备中的备不是对外提供的,备的作用是待“主”crash的时候成为主
🎈🎈接下来呢,我们讨论复制系统的一个重要细节(复制策略):复制是 同步(synchronously) 发生还是异步(asynchronously) 发生
同步/异步
如下图:
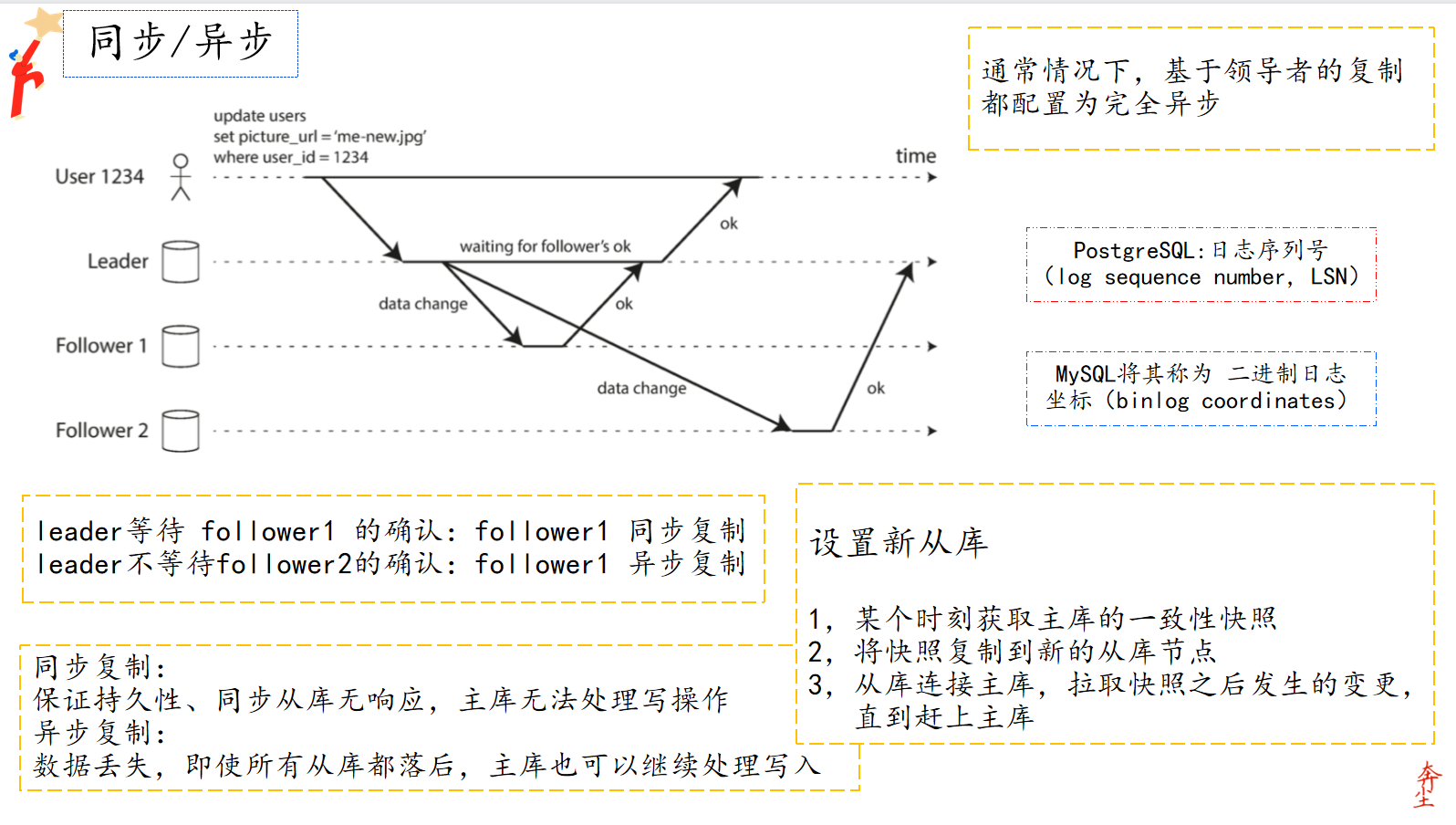
同步 & 异步
1⃣ 用户 $id=1234$ 的用户向主库提交数据变更请求
2⃣ 主库将数据变更同步给从库1(Follower1) ,并且等待从库1(Follower1)的响应,这里从库1(Follower1)复制的方式是同步
3⃣ 主库将数据变更同步给从库2(Follower),但是不等待从库2(Follower2)的确认,这里从库2(Follower2)的复制方式是异步
整体的配置方式也被称作是半同步。我们来一起看下同步和异步复制的优劣势:
🅰 同步复制能够保证数据可靠性,但是如果从库迟迟不能响应主库,主库就不能接收新的读写请求
🅱 异步复制的优点是,即便从库落后了,主库也可以继续处理写入请求,劣势是无法保证数据一致性
我们再来看一下设置新从库的步骤:
1⃣ 获取某个时刻主库的一致性快照
2⃣ 将快照复制到从库节点
3⃣ 从库连接主库,拉取快照之后发生的数据变更。拉取快照之后的变更,往往快照和主库复制日志关联,不同的数据库对于这个关联关系实现有着不同的名称:
- PostgreSQL 的叫做日志序列号(log sequence number, LSN)
- MySQL将其称为 二进制日志坐标(binlog coordinates)
🎈🎈 从库失效的问题很好解决,从库在重新和主库建立连接之后,可以从日志知道最后一个失败的事务。然后开始追赶主库。如果主库失效了,该如何处理呢?
处理故障节点
主库失效如何处理?
1⃣ 确认主库失效
2⃣ 选择一个新的主库,让所有的副本达成一致意见(共识~consensus~问题)
3⃣ 重新配置新的主库,并且启用新的主库
一些挑战:
- 如果使用异步复制,发生的数据丢失问题,GitHub,MySQL从库切换为主库事故
- 脑裂的情况,设置新的主库之后,老的主库又一次活过来了,可能会存在两个主库的情况,同时接受写入,可能会导致数据损坏,解决的方案可能是,发送
killcomand 去干掉一个主库 - 宣告主库死亡的阈值,主库在宣告死亡前,超时时间的设置,设置太长意味着恢复时间长,太短就会发生不必要的切换
基于主库的复制底层是如何工作的?
1⃣ 基于语句的复制,有非确定性函数、自增列的问题
2⃣ 传输,预写式日志(WAL,Write Ahead Log),日志包含所有数据库写入的仅追加字节序列,可以将其发给从库,比如说PostgreSQL 、Oracle。缺点是数据过于底层,WAL包含哪些磁盘块中的哪些字节发生了更改。这使复制与存储引擎紧密耦合,对数据库版本不友好,会对运维升级数据库造成困难
MySQL数据库中有2种日志:redo log 和 binlog ,其中的redo log的实现方式即为WAL,先写日志,在罗盘
3⃣ 逻辑日志复制(基于行),也即复制日志和存储引擎存储的日志采用不同的格式,这种复制日志被称为逻辑日志,逻辑日志有一下特点:
- 对于插入的行,日志包含所有列的新值
- 对于删除的行,日志包含足够的信息来唯一标识已删除的行。通常是主键,但是如果表上没有主键,则需要记录所有列的旧值
- 对于更新的行,日志包含足够的信息来唯一标识更新的行,以及所有列的新值(至少所有已更改的列的新值)
逻辑日志,可使领导者和跟随者能够运行不同版本的数据库软件甚至不同的存储引擎。MySQL的binlog日志有三种格式,分别是statement、row、mixed,现通常使用row模式,即逻辑日志的形式,MySQL binlog 使用row模式就是当前描述的这种方式
模式下数据库的变更流可以应用在MySQL从库,或者Debezium/Cancel解析后推送至三方系统(消息代理Kafka、存储系统)
4⃣ 基于触发器的复制,触发器能够实现,在数据库系统中发生数据更改(写入事务)时,自动执行的自定义应用程序代码,不同于数据库系统实现的复制
复制延迟问题
A-什么是最终一致性?
从库有可能落后于主库,此时同一个查询打到主库和从库,会得到不一样的结果,这种不一致只是一个暂时的状态,如果停止写入数据库并等待一段时间,从库最终会赶上并与主库保持一致。这种效应被称为 最终一致性(eventually consistency)
B-什么是写后读一致性?
在异步复制策略中,用户向主提交了新数据,但是该用户的查询打到了从库,这种情况下,我们需要写后读一致性(read-after-write consistency),即:自己刚刚更新的内容,再去查询的时候,可以获取到更新
具体实现的方式有:
- 读用户可能已经修改过的内容时,都从主库读。一个简单的规则是:从主库读取用户自己的档案,在从库读取其他用户的档案
- 客户端记住最近一次写入的时间戳(可以是逻辑时间戳),如果该时间戳已经传播到了从库,从从库读取没问题,否则从主库读
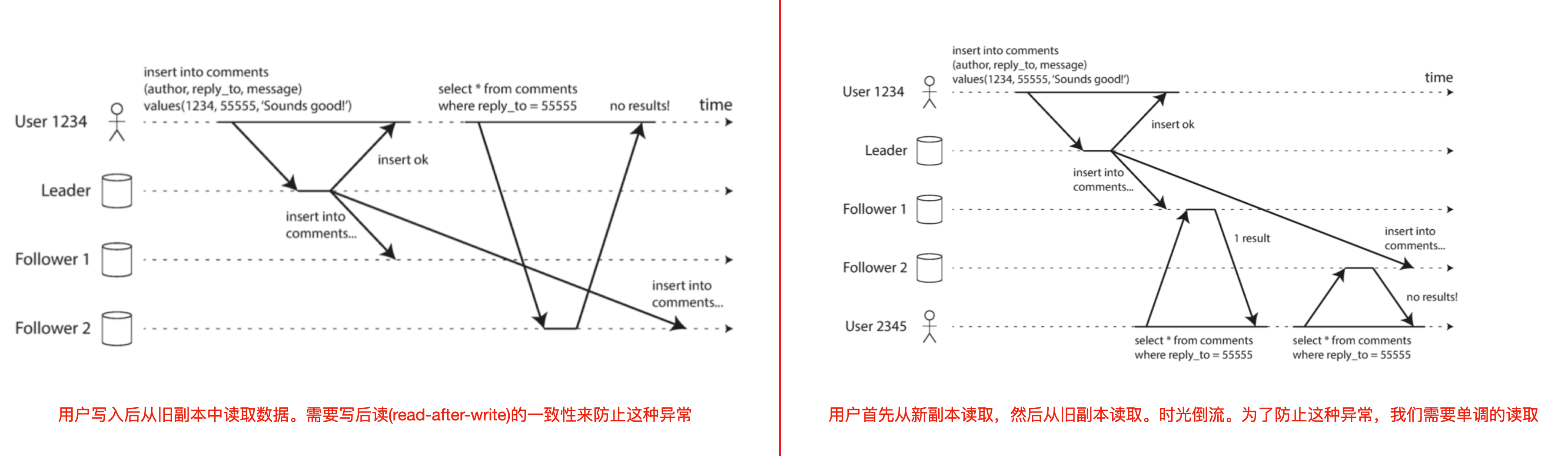
写后读一致性保证 & 单调读一致性保证
C-什么是单调读?
用户首先从新副本读取,然后从旧副本读取。时光倒流,我们需要单调读一致性
实现单调读取的一种方式是,确保每个用户总是从同一个副本进行读取(不同的用户可以从不同的副本读取)。例如,可以基于用户ID的散列来选择副本,而不是随机选择副本。但是,如果该副本失败,用户的查询将需要重新路由到另一个副本
D-什么是一致前缀读?
如果某些分区的复制速度慢于其他分区,那么观察者在看到问题之前可能会看到答案,我们需要提供某种保证,如果一系列写入按某个顺序发生,那么任何人读取这些写入时,也会看见它们以同样的顺序出现
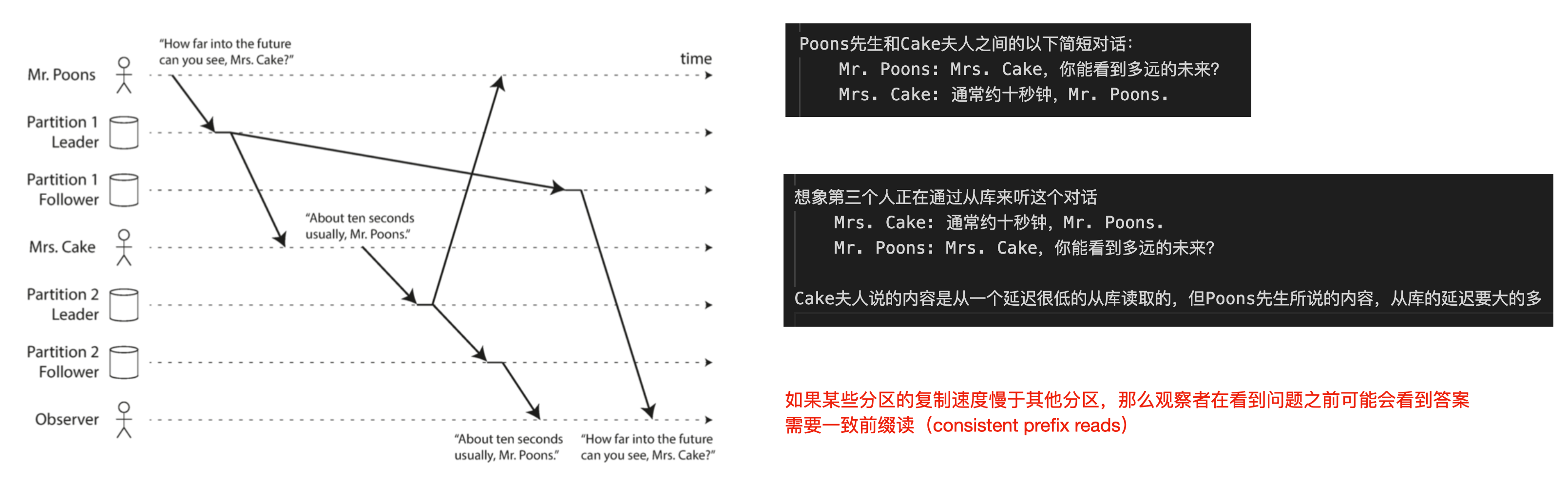
一致前缀度保证
许多分布式数据库中,不同的分区独立运行,因此不存在全局写入顺序:当用户从数据库中读取数据时,可能会看到数据库的某些部分处于较旧的状态,而某些处于较新的状态。
一种解决方案是,确保任何因果相关的写入都写入相同的分区。对于某些无法高效完成这种操作的应用,还有一些显式跟踪因果依赖关系的算法,本书将在“一致性与共识”一节中再次聊聊这个问题
多主复制的问题
多领导者复制的最大问题是可能发生写冲突,这意味着需要 解决冲突

两个主库同时更新同一记录引起的写入冲突
无主复制
在无主复制,客户端的写入和读取,都请求到所有的副本,副本的写入有可能失败,有可能成功;读取时,选择按照法定人数(5个节点,3个节点返回数据相同)的数据回写到写入失败的节点。同时后台进程追踪节点之间的差异,趋势数据的收敛(因为有一些键没有读请求)
A-什么是并发?
为了定义并发性,确切的时间并不重要:如果两个操作都意识不到对方的存在,就称这两个操作并发
第6章-分区
分区28是一种切分大数据集的方法,即一份数据切成多块,分区的目的是为了可扩展性,从而提高吞吐量。在实践中,分区通常和复制结合使用,每个分区的副本将处在多个节点上,以此获得容错能力。下图是主从复制模型下,分区和复制相结合的示意图:
28:分区有很多中叫法,比如Solr Cloud中被称为分片(shard),在HBase中称之为区域(Region),Bigtable/Kudu中则是表块(tablet,Cassandra和Riak中是虚节点(vnode), Couchbase中叫做虚桶(vBucket),但是分区(partition)是约定俗成的叫法

分区和复制的实例
键值数据的分区方式
分区最核心的问题是
🅰 避免倾斜(skew),即热点数据处理,放的角度
🅱 处理访问路由问题,即查询性能的保证,取的角度
下面我们介绍几种常见的分区方式:
1⃣ 按照key的范围分区,这种方式天生可以解决访问路由的问题,对于热点数据,可根据数据状况进行拆分,Hbase,BigTable使用这种策略。在处理时间范围分区时,为避免一直写当前时间对应分区的 写入过载 问题,可引入其他列值+时间做分区
按照范围分区,可以手动调整分区范围,使得分区尽量均衡
2⃣ 散列29分区。散列分区可以很好的处理热点问题,弊端是查询能力无法保证,因为曾经相邻的密钥分散在所有分区中,这意味着如果执行范围查询,则该查询将被发送到所有分区中

哈希的方式处理热点问题
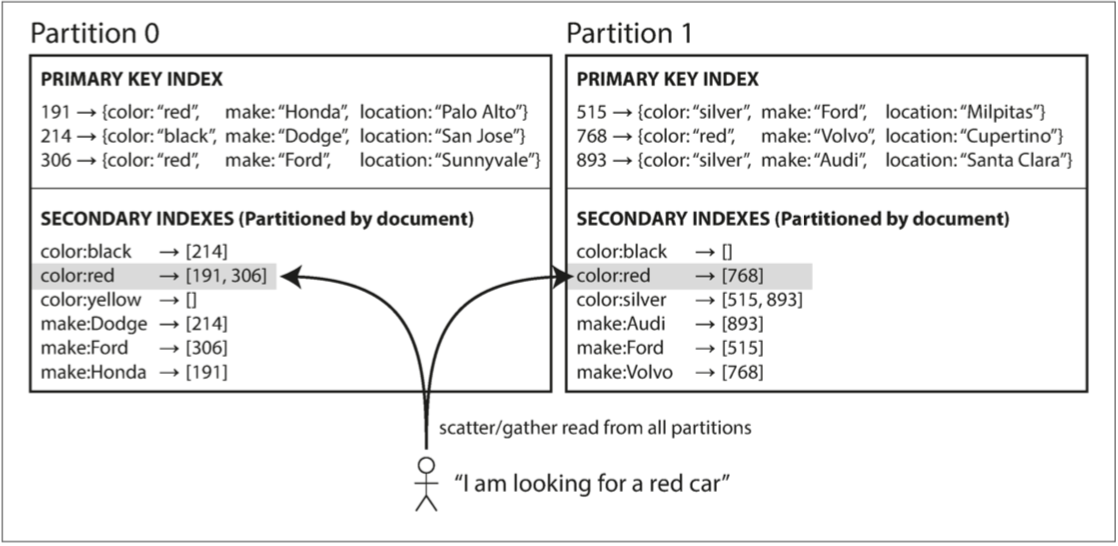
基于文档的二级索引分区
🅱 基于关键词(term-based)的分区,对所有分区的数据构建全局索引的同时,对全局索引进行分区。这种索引称为关键词分区(term-partitioned) 30,关键词分区的全局索引的优势在于不需要分散/收集所有分区,客户端只需要向包含关键词的分区发出请求。全局索引的缺点在于写入速度较慢且较为复杂,因为写入单个文档现在可能会影响索引的多个分区。在实践中,全局二级索引的更新通常是异步的
(在任何时候)使用关键词本身进行分区适用于范围扫描,而对关键词的哈希分区提供更好的负载均衡能力
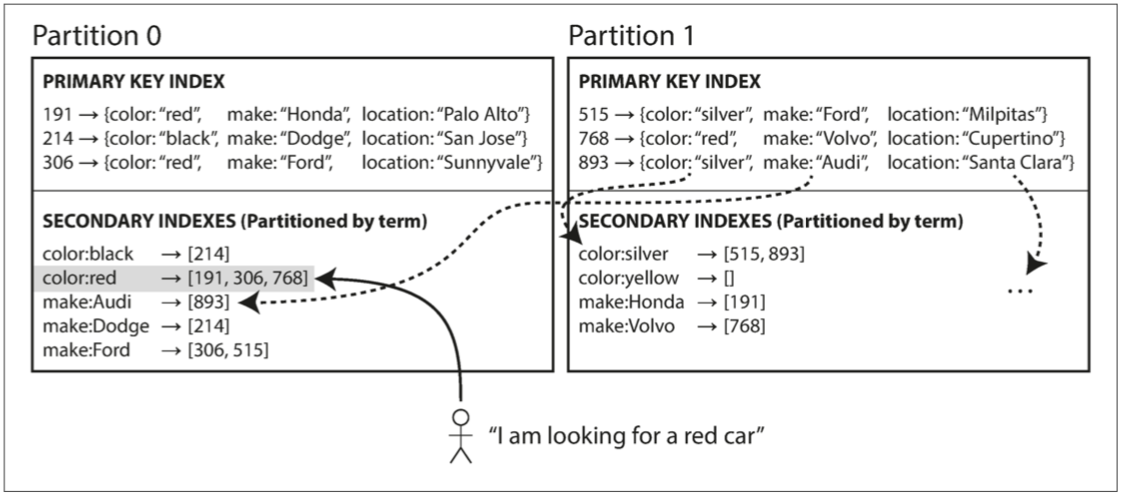
基于关键词的二级索引分区
30. 我们搜索的关键词决定了次级索引的分区方式,因此称之为关键词索引,关键词(term)一词来源于全文搜索索引(一种特殊的次级索引)。 ↩
分区再平衡
将负载(数据存储和读写请求)从集群中的一个节点,向另一个节点移动的过程称为再平衡(reblancing),再平衡应该满足一下几个要求:
- 再平衡之后,负载(数据存储,读取和写入请求)应该,在集群中的节点之间公平地共享
- 再平衡发生时,数据库应该继续接受读取和写入
- 节点之间只移动必须的数据32,以便快速再平衡,并减少网络和磁盘I/O负载
32. 即一致性哈希解决的问题,一致性哈希的主要应用就是降低路由成本 ↩
相应的,我们有三种分区方式,来进行处理
1⃣ 固定数量的分区,创建比节点更多的分区,并为每个节点分配多个分区,如果一个节点被添加到集群中,新节点可以从当前每个节点中窃取一些分区,直到分区再次公平分配,如下图。Riak,Elasticsearch使用了这种再平衡的分区方式
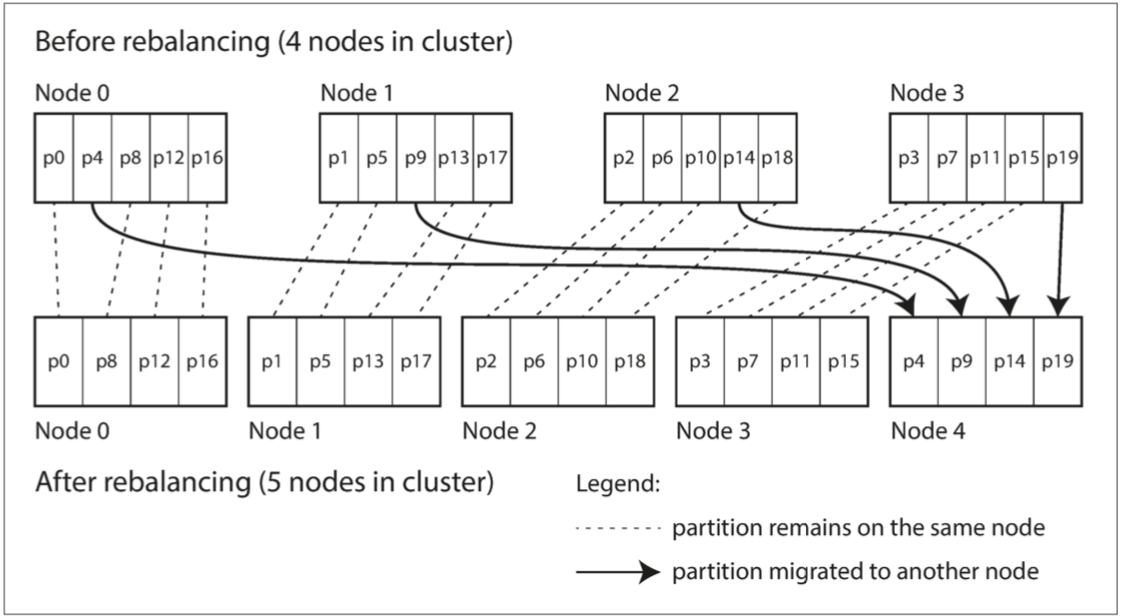
新节点从旧节点中窃取一些分区
2⃣ 动态分区,当分区增长到超过配置的大小时(在HBase上,默认值是10GB),会被分成两个分区,每个分区约占一半的数据,反之进行合并,类似B树的页分裂/合并的过程
3⃣ 分区数与节点数成正比,节点数量不变时,每个分区的大小与数据集大小成比例地增长,节点数增加时,分区数也增加,分区数据变少
请求路由
数据集已经分割到多个机器上运行的多个节点上,那么当客户想要发出请求时,如何知道要连接哪个节点呢?即请求应该路由给谁?这个问题也可以概括为服务发现(service discovery),有目前以下三种方案:
1⃣ 允许客户联系任何节点(例如,通过循环策略的负载均衡(Round-Robin Load Balancer))。如果该节点恰巧拥有请求的分区,则它可以直接处理该请求,否则,它将请求转发到适当的节点,接收回复并传递给客户端
2⃣ 首先将所有来自客户端的请求发送到路由层,它决定了应该处理请求的节点,并相应地转发。此路由层本身不处理任何请求,它仅负责分区的负载均衡
3⃣ 要求客户端知道分区和节点的分配。在这种情况下,客户端可以直接连接到适当的节点,而不需要任何中介
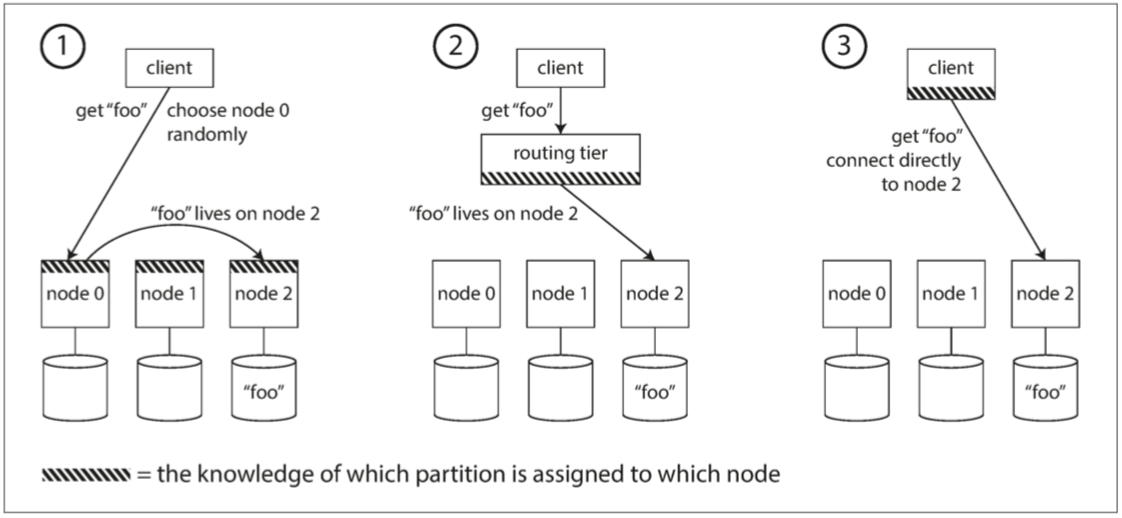
客户端连接到分区的3种方式
以上三种方式都会面临一个问题:作出路由决策的组件(节点之一/路由层/客户端),如何了解分区-节点之间的分配关系变化?许多分布式数据系统都依赖于一个独立的协调服务(如ZooKeeper)来跟踪集群元数据,每个节点在ZooKeeper中注册自己,ZooKeeper维护分区到节点的可靠映射
其他参与者(如路由层或分区感知客户端)可以在ZooKeeper中订阅此信息。 只要分区分配发生的改变,或者集群中添加或删除了一个节点,ZooKeeper就会通知路由层使路由信息保持最新状态。HBase,SolrCloud和Kafka,使用ZooKeeper来跟踪分区分配
MongoDB具有类似的体系结构,但它依赖于自己的配置服务器(config server) 实现和mongos守护进程作为路由层
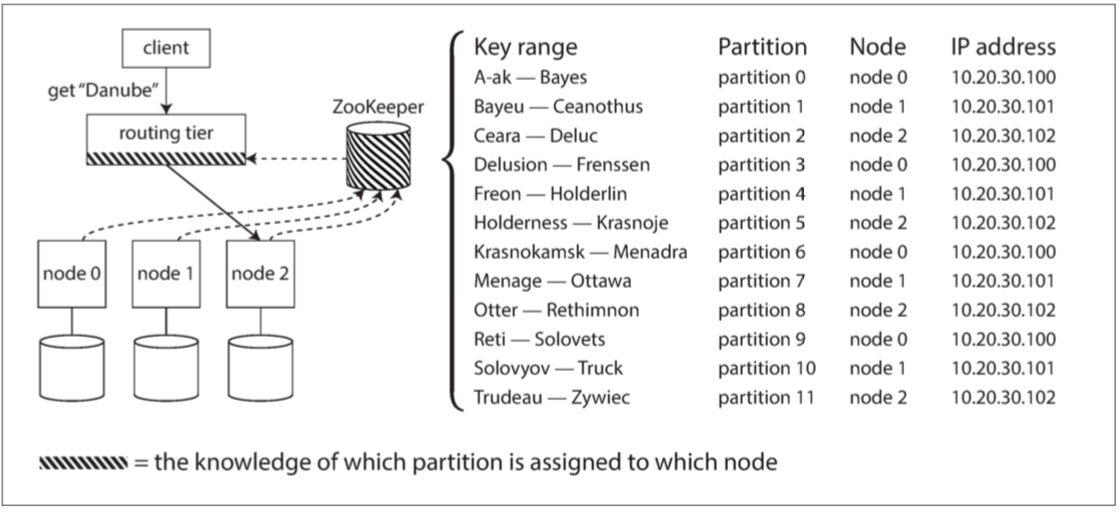
路由层如何感知分区和节点之间的关系
第7章节-事务
事务的起源
很早就接触事务这个概念,关于事务网上的文章动不动就把转账的的例子拿出来讲,坑的时候有的压根就没有讲明白,事务的概念事务要不就执行成功,要不执行失败,只有这2种状态也背的烂熟,也知道事务的4大特性ACID (原子性、一致性、隔离性、持久性),但是这么些年从来没有思考过:为什么要有事务?他解决了什么样子的问题/痛点?那么我们带着这个问题来回顾一下事务起源:

事务的起源
上图中有一个名为猪小明的程序员,抱着电脑正在疯狂的写代码(开发应用程序),其中应用程序需要透过网络在数据库中存放数据/获取数据,数据库软件依托于是操作系统,操作系统的底层是一些计算机硬件(存储介质/磁盘/缓存/Cache/RAM /ROM/CPU/主板等)。整个过程中,各个环节都有可能出错,比如:
1⃣ 网络中断,客户端和应用程序服务之间,服务和数据库之间
2⃣ 数据库软件本身挂掉了,硬件发生故障9
9. 关于硬件故障:硬件故障率是很高的,磁盘在进行大量的读写之后失效的概率是很高的,IDC数据中心对物理环境的要求是很苛刻的,为了降低温度空调不够用,甚至把数据中心搬到山洞里,比如阿里在贵州云南的IDC,地板使用静电地板,每个机房入口的挡鼠板比膝盖还高,供电都是双路供电等。 ↩
3⃣ 应用程序在进行写入的时候,写到一半,自己崩溃了
4⃣ 多个客户端同时操作数据库,覆盖彼此的更新
5⃣ 客户写到一半的数据,被另外一个客户读取到
6⃣ 客户之间的竞争导致的令人惊讶的错误
所有的这一些都需要应用程序的开发者,猪小明去解决,但是这个工作量是巨大的,应用开发应该专注于业务,而不是通用问题的处理,这些问题应该留给下层的数据库去处理。所以为了简化应用编程模型 ,事务诞生了。通过使用事务,应用程序可以自由地忽略某些潜在的错误情况和并发问题,因为数据库会替应用处理好这些问题
1974年的时候,IBM的圣荷西研究中心发布了,第一款提供优秀的事务处理能力的关系型数据库R[seminal-project]。时至今日开发者已经习惯了事务,他们觉得事务是理所当然的,是天然就存在的,然而并不是,了解事务出现的历史,我们可以发现事务是我们的计算机先驱们为了解决一揽子问题,提供的一种解决方案
ACID
谈及事务,必谈事务的4大特性ACID;那么ACID 分别指的是什么?
*Atomicity : 原子性。能够在错误时中止事务,丢弃该事务进行的所有写入变更的能力,可以理解为可终止性。假设没有原子性,如果有多次更改,但是更改发生过程中发生了错误,应用程序很难判断哪些更改生效了,哪些没有生效。如果有了原子性,应用程序可以确定的知道在发生错误时,所有更改没有生效。*没有原子性,错误处理就会变的很复杂
区别于线程的原子操作:多线程中的原子操作描述的是,如果一个线程执行一个原子操作,意味着另外一个线程无法看到该原子操作的中间结果。而这个特性在ACID中是 I(isolation) 来描述的
*Consistency:一致性。在事务中,一致性是指:对数据的一组特定陈述必须始终成立,即为不变量*,如在会计系统中,所有账户整体上必须借贷相抵,转账过程中,加钱和减钱是相等的。原子性,隔离性和持久性是数据库的属性,而一致性(在ACID意义上)是应用程序的属性
这是一个一词多意的词,用行话来说,这个词被重载了
有别于副本一致性,比如在单主复制的模式下,采用异步复制的方式,收敛最终一致
还有大家有可能会听过一致性hash(一致性散列)那是一种为了避免重新分区带来的复杂度提高的一种解决方案
- CAP定理中,C指的是线性一致性
*Isolation:隔离性。竞争条件下,同时执行的事务是相互隔离的,下图是两个客户之间的竞争状态同时递增计数器的图述。*缺乏隔离性,就会导致并发问题
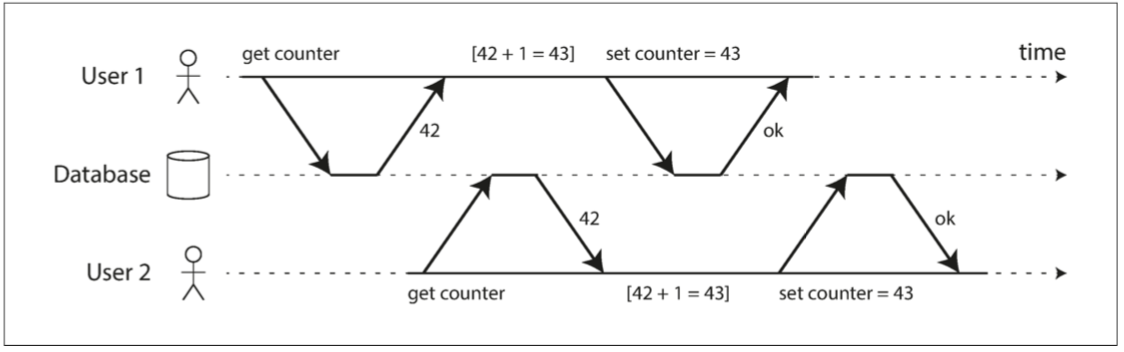
两个客户之间的竞争状态同时递增计数器
*Durability* :持久性。持久性是事务的一个承诺,也即事务完成后,即便发生硬件故障或者数据库崩溃,写入的任务数据也不会丢失。持久性过去一般被认为写入了非易失性存储介质
单对象操作和多对象操作
单一对象操作,所谓单对象操作中的对象,指的是数据库中被修改的对象,比如你正在向数据库写入一个20KB的Json文档,以下场景可能会发生:
1⃣ 在发送第一个10KB之后,网络连接中断,数据库是否存储了不可解析的10KBJSON片段?
2⃣ 在数据库正在覆盖的磁盘上前一个值的过程中电源发生故障,是否最终将新旧值拼接在一起?
3⃣ 如果另一个客户端在写入过程中读取该文档,是否会看到部分更新?
这里的 JSON对象,就是单一对象,单一对象是相对于多对象而言的,待会我们会谈及到多对象。为了针对以上的问题,存储引擎会在单个对象上提供原子性和隔离性,如此一来:
🅰 原子性通过WAL(即redo-log)日志来实现崩溃恢复
🅱 使用每个对象的锁来实现隔离(每次仅仅允许一个线程访问对象)
除了单对象操作,还有就是CAS(Compare-and-set),防止多个客户端同时写入同一个对象时的更新丢失,即当值没有并发被其他人修改的时候,才允许执行写入操作。CAS操作和单对象操作,被称作是轻量级事务。事务通常更多的强调 : 将多个对象的多个操作合并为一个执行的单元的机制
何为多对象? 在操作数据库时,需要协调写入几个不同的对象:
- 关系模型中,一个表中的行对另外一个表的外键引用。你得确保外键是最新的,可用的
- 在字段冗余的场景中,单个字段在多处被存储,你得保证这几处是同步的
- 二级索引的数据库中,数据更新的时候,二级索引也需要更新
在这种情形下,需要使用事务来进行处理
接下来我们会讲述隔离级别,在讲述隔离级别之前,明确两点:
🅰 隔离级别是对事务的4大特性之一隔离性上进行了一个等级划分,数据库标准的事务隔离级别包括:
- 读未提交(read uncommitted)
- 读已提交(read committed)
- 可重复读/快照隔离(repeatable read)
- 串行化(serializable)
🅱 隔离级别最高是可序列化,表示同一时间只能有一个事务。隔离级别和性能之间是一个负相关的关系,也就是说隔离级别越高,数据一致性的保证越好,但是性能越差。隔离级别是数据一致性和服务性能的一场博弈。为了实现更优的性能,我们需要较弱的隔离级别
下面介绍这些弱隔离级别
读已提交
最基本的弱隔离级别是,读已提交,它提供了两个保证:
- 没有脏读(dirty reads),从数据库读时,只能看到已提交的数据
- 没有脏写(dirty writes),写入数据库时,只会覆盖已经写入的数据
另外读未提交:
- 可以防止脏写
- 但是不能够防止脏读
下图是一个没有脏读的例子:可以看到直到用户1提交了之后,用户2才看到提交之后的值x=3,而在这之前用户1只能看到x=2

用户2只有在用户1的事务已经提交后才能看到x的新值
那么为什么要防止脏读呢?主要是下面两个原因:
1⃣ 如果事务需要更新多个对象,脏读取意味着另一个事务可能会只看到一部分更新。比如说下面这个电子邮件的例子。事务还没有提交,但是用户2看到了未读邮件,可是未读邮件的数量却还是旧值
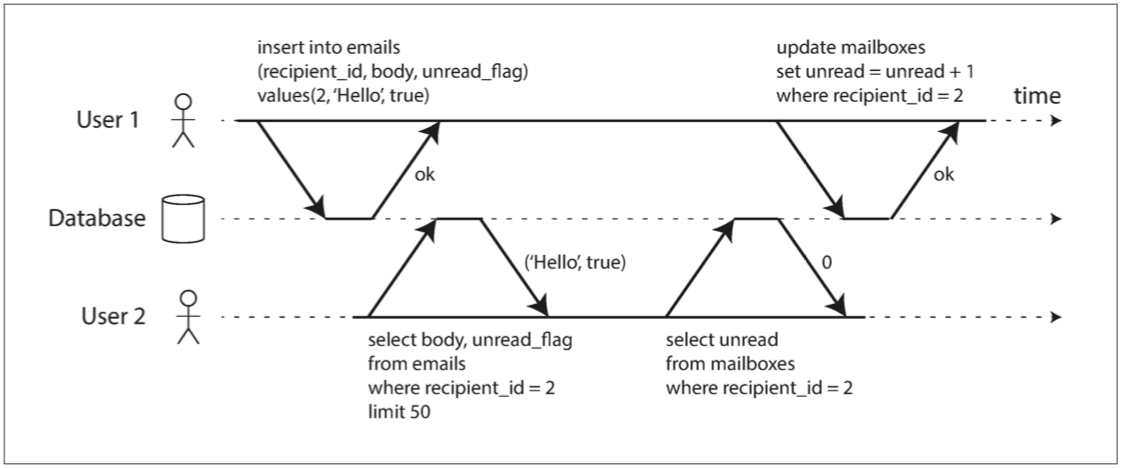
一个事务读取另一个事务的未被执行的写入(“脏读”)
2⃣ 若数据库允许脏读,意味着一个事务可能会看到稍后需要回滚的数据,即从未实际提交给数据库的数据。比如下面的例子中读到了未提交的数据,但是后面事务回滚了
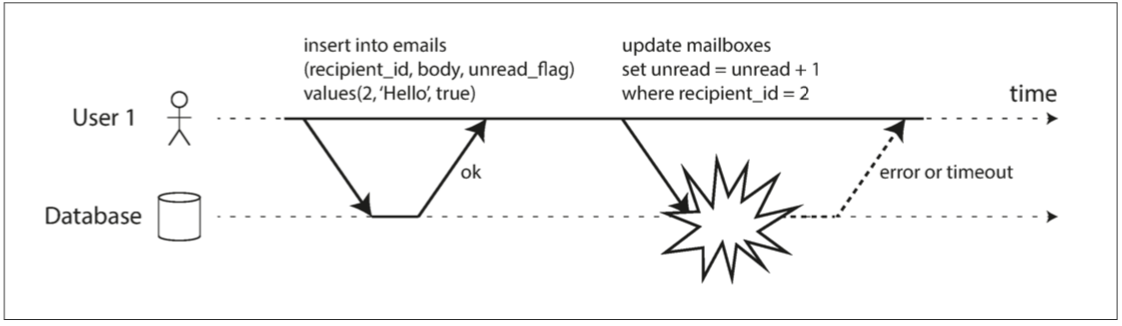
原子性确保发生错误时,事务先前的任何写入都会被撤消,以避免状态不一致
两个事务同时更新数据库中的对象,先前的写入没有提交,后面的写入覆盖这个尚未提交的值,这就是脏写。没有脏写,意味着在写入数据库时,只会覆盖已经写入的数据。在读已提交的隔离级别上运行的事务必须防止脏写,通常是延迟第二次写入,直到第一次写入事务提交或中止为止。下图是脏写发生的示例,发票属于Alice; 销售属于Bob’
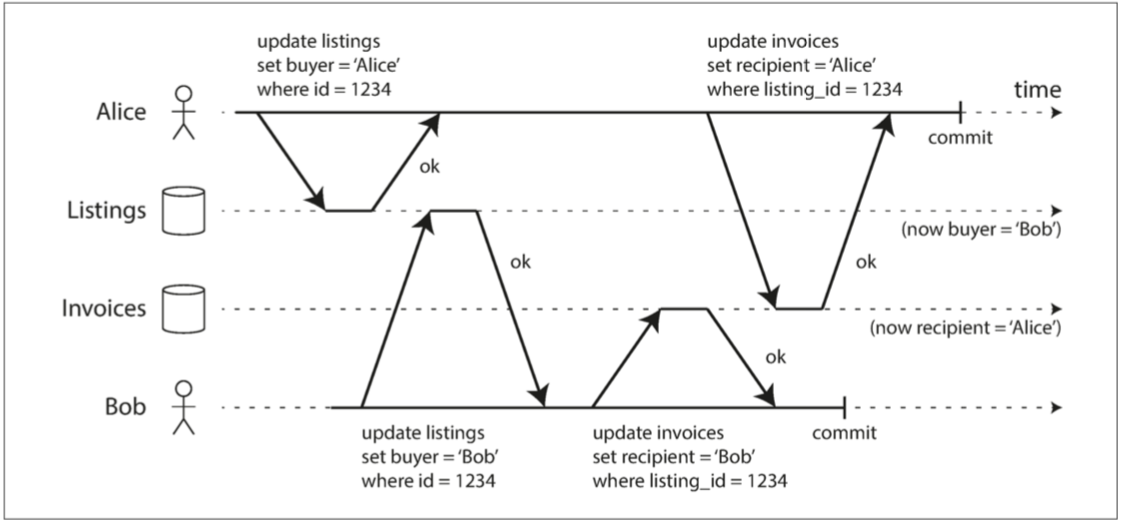
如果存在脏写,来自不同事务的冲突写入可能会混淆在一起
实现读已提交
读已提交是一种非常Fashion的一个隔离级别,有很多数据库软件将读已提交设置为默认的隔离级别,比如Oracle 11、PostgreSQL、SQLServer 2012 ,那么如何实现
1⃣ 无脏写保证:数据库通过使用 行锁(row-level lock)10 来防止脏写;即当事务想要修改特定对象时,必须获取该对象的锁,然后必须持有该锁,直到事务被提交或终止。这种锁定是读已提交模式(或更强的隔离级别)的数据库自动完成的
10. 行锁满足两阶段锁协议,两阶段锁协议是说:锁需要的时候才加上的,在事务结束的时候才释放;同时行锁也是2PL(2阶段锁定),在当前事务写入时必须持有排它锁,直到事务提交才释放排它锁。 两阶段锁协议和2pl说的是一个事情 ↩
2⃣ 无脏读保证:MVCC11 ,数据库都会记住旧的已提交值,和当前持有写入锁的事务设置的新值。 当事务正在进行时,任何其他读取对象的事务都会拿到旧值。 只有当新值提交后,事务才会切换到读取新值
11. 同一条记录在系统中可以存在多个版本,这就是数据库的多版本并发控制; ↩
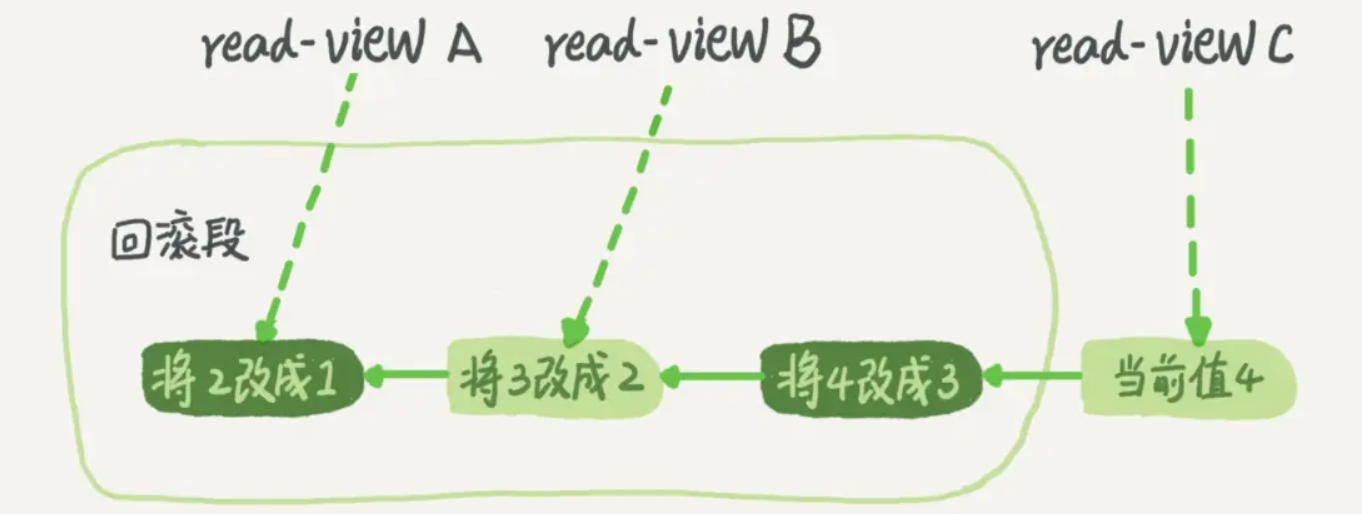
一个值从1按顺序修改为4的过程。在读已提交的隔离级别下,仅仅保留为提交版本和提交前版本2个版本
读已提交的隔离级别无法避免不可重复读的情况,下面的例子:爱丽丝在银行有1000美元的储蓄,两个账户,每个500美元;现在一个事务从她的一个账户中,转移了100美元到另一个账户
- Alice在转账事务之前查询了账户1的金额为500元
- Alice在转账之后完成之后,查询了账户2的金额为400元
- 此时账户的总额为900元,Alice就很疑惑为什么自己的钱少了?
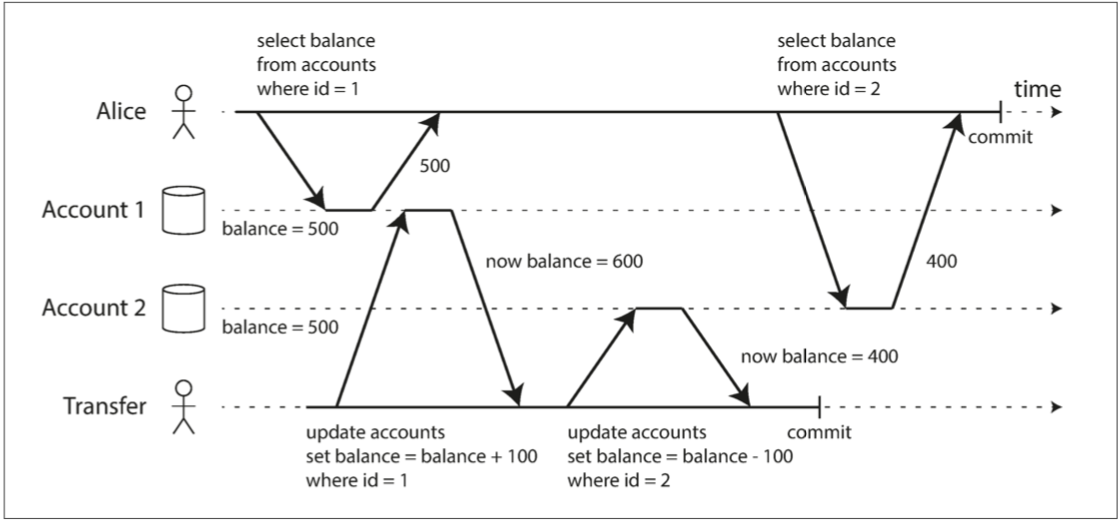
读取偏差:Alice观察数据库处于不一致的状态
这种,这种异常被称为不可重复读(nonrepeatable read),如果Alice在事务结束时再次读取账户1的余额,她将看到与她之前的查询中看到的不同的值(600美元)。在读已提交的隔离条件下,不可重复读可能会发生
实现快照隔离
快照隔离的另外一个叫法是可重复读,快照隔离和读已提交一致,使用写锁来防止脏写,也就是正在进行写入的事务会阻止另外一个事务修改同一个对象。读取没有任何的锁定,写不阻塞读,读不阻塞写,RC下也是,数据库使用多版本并发控制(MVCC, multi-version concurrentcy control) 数据库保留一个对象的几个不同的提交版本。另外使用MVCC实现快照隔离的存储引擎通常也会使用MVCC来实现读已提交(一个对象的两个版本:提交的版本和被覆盖但尚未提交的版本)
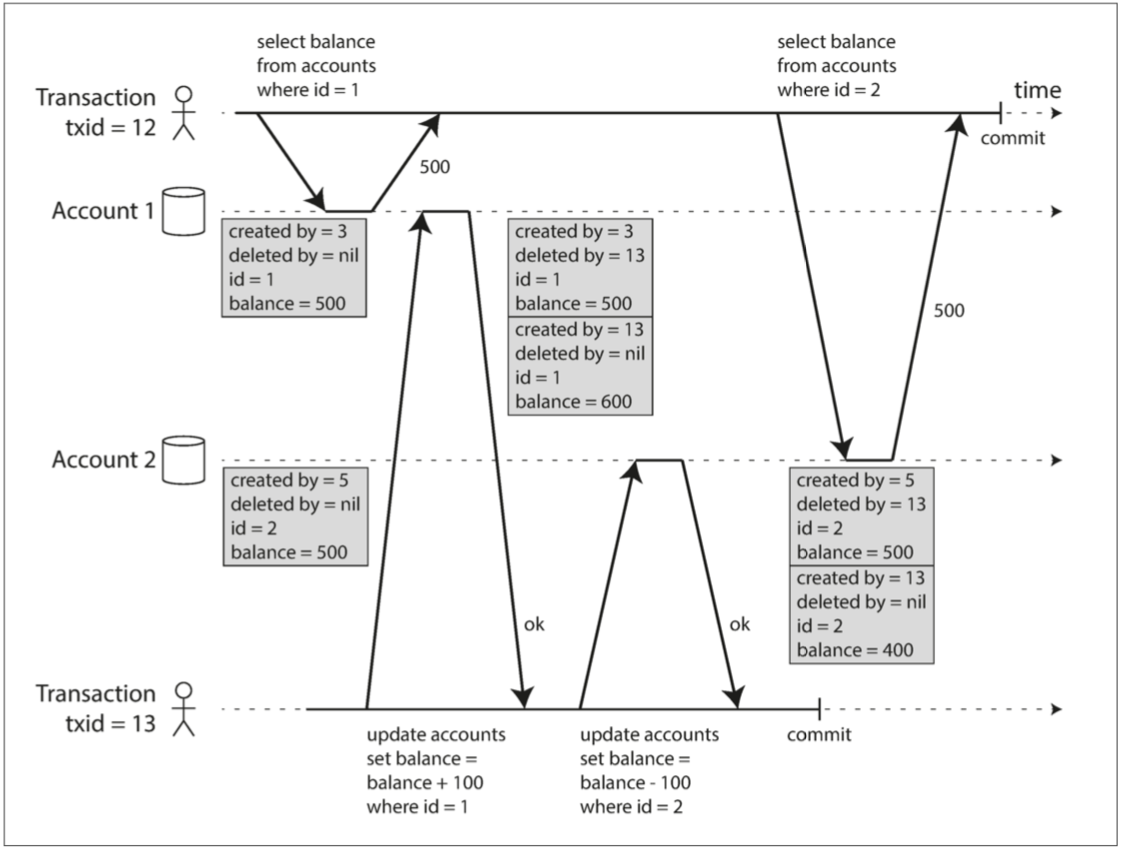
使用多版本对象实现快照隔离
那么我们再来看一下一致性快照的可见性规则:也就是说当一个事务从数据库中读取时,事务ID用于决定它可以看见哪些对象,看不见哪些对象。规则如下:
1⃣ 在每次事务开始时,数据库列出当时所有其他(尚未提交或中止)的事务清单,即使之后提交了,这些事务的写入也都会被忽略
2⃣ 被中止事务所执行的任何写入都将被忽略
3⃣ 由具有较晚事务ID(即,在当前事务开始之后开始的)的事务所做的任何写入都被忽略,而不管这些事务是否已经提交
4⃣ 所有其他写入,对应用都是可见的
更简单的讲,对于隔离级别的实现数据库里面会创建一个视图,访问的时候以视图的逻辑结果为准
1⃣ “读未提交”隔离级别下直接返回记录上的最新值,没有视图概念
2⃣ 在“读提交”隔离级别下,这个视图是在每个 SQL 语句开始执行的时候创建的
3⃣ 在“可重复读”隔离级别下,这个视图是在事务启动时创建的,整个事务存在期间都用这个视图
4⃣ “串行化”隔离级别下直接用加锁的方式来避免并行访问
丢失更新
前面描述的是读-写并发场景下,只读事务在并发写入时候能看到什么,另外一个问题是两个事务并发写入的问题,即写-写冲突。如下图就是丢失更新的例子
丢失更新:两个客户之间的竞争状态同时递增计数器
解决写-写冲突有很多方式,比如原子写(数据库提供),显示锁定,比较并设置(CAS)
1 | -- 数据库提供原子更新操作,消除在应用程序代码中执行读取-修改-写入序列的需要 |
在MySQL中,使用当前读12的方式来处理写-写冲突,下图为RR隔离级别下,写-写冲突的例子
12. 更新数据是先读后写的,读只能读当前已提交的最新值,这就是当前读 ↩

写偏差
如果两个事务读取相同的对象,然后不同的事务可能更新不同的对象,则可能发生写偏差(写偏差包含丢失更新)
下面是写偏差的例子,描述的是一个医生轮班管理程序,医院有以下的要求:至少有一位医生在待命,现在Alice 和 Bob 两位值班医生都感觉到不适,决定请假:
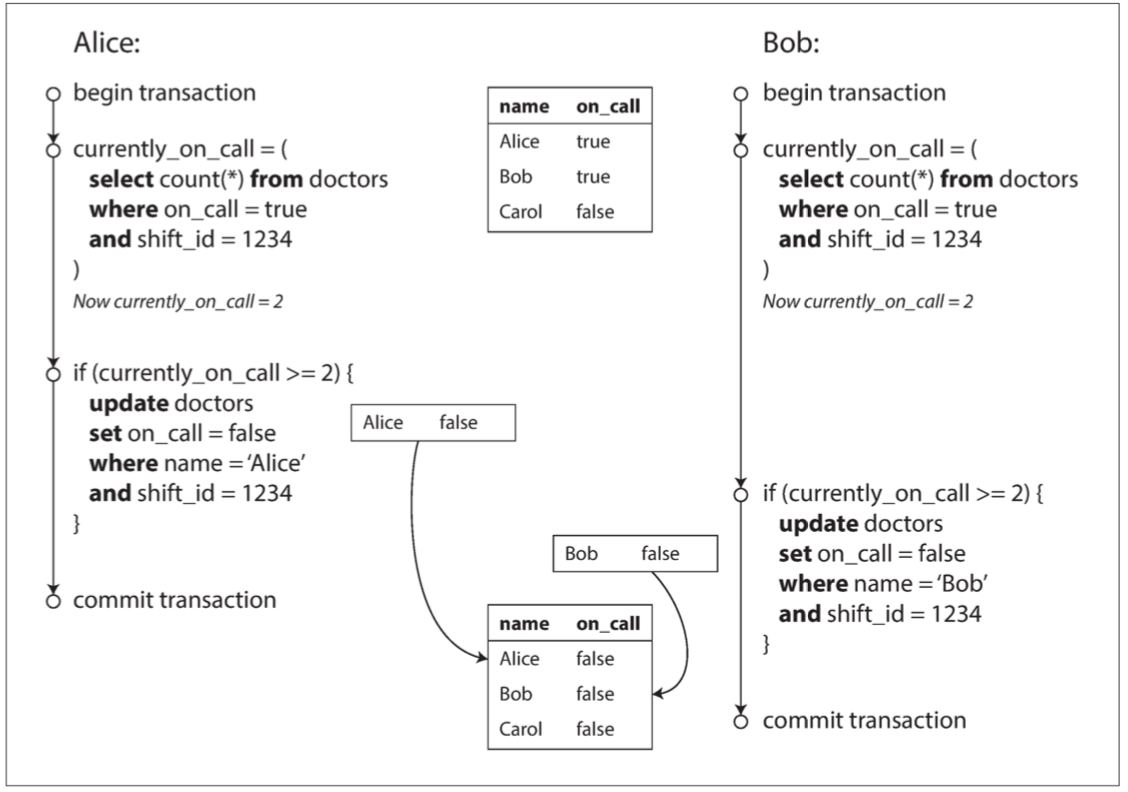
写入偏差导致应用程序错误的示例
在多个事务更新同一个对象的特殊情况下,就会发生脏写或丢失更新(取决于时机) 防止写偏差,需要使用序列化隔离级别
幻读
一个事务中的写入改变另一个事务的搜索查询的结果,称为幻读
下图是一个幻读的例子:
幻读会导致写偏差。快照隔离避免了只读事务中的幻读,但是无法避免读写事务中的幻读。从上面的例子来看,幻读的问题貌似是没有对象可以加锁。人为的引入锁对象的方式被称之为物化冲突

干扰事务 干扰 主事务的执行
🅰 主事务,检测表中是否有id=1的记录,没有则插入(for update 没有用,因为没有加锁对象),这是我们期望的正常业务逻辑
🅱 干扰事务,目的在于扰乱,主事务的正常的事务执行
我们看到,干扰事务率先执行了,主事务发生了幻读,因为主事务读取的状态并不能支持它的下一步逻辑,感觉看到了幻影。上例中是干扰事务妨碍了主事务搜索结果。在MySQL中,使用间隙锁(下文会涉及到)来处理幻读问题。不可重复读侧重表达读-读,幻读则是说读-写,用写来证实读的是鬼影
序列化/串行化
对串行化的理解应当是这样的:一次只执行一个事务。设计单线程的系统有时候比支持并发的系统更好,因为它可以避免协调锁的开销。数据库的早期,数据库意图包含整个用户的活动流程,但是如今的web应用,一个事务不会跨越多个请求,事务会在同一个HTTP请求被提交
两阶段锁定-2PL
30年以来,数据库中只有一种广泛使用的序列化算法:两阶段锁定(2PL,two-phase locking)。两阶段这个名字的来源:第1阶段(当事务正在执行时)获取锁,第2阶段(在事务结束时)释放所有的锁
2PL要求只要没有写入,就允许多个事务同时读取同一个对象。但对象只要有写入(修改或删除),就需要独占访问(exclusive access) 权限。锁可以处于共享模式,可以处于独占模式:
1⃣ 若事务要读取对象,则须先以共享模式获取锁。允许多个事务同时持有共享锁。但如果另一个事务已经在对象上持有排它锁,则这些事务必须等待
2⃣ 若事务要写入一个对象,它必须首先以独占模式获取该锁。没有其他事务可以同时持有锁(无论是共享模式还是独占模式),所以如果对象上存在任何锁,该事务必须等待
3⃣ 如果事务先读取再写入对象,则它可能会将其共享锁升级为独占锁。升级锁的工作与直接获得排他锁相同
4⃣ 事务获得锁之后,必须继续持有锁直到事务结束(提交或中止)
由于加了这么多的锁,可能会发生死锁情况,死锁及死锁检测的内容可以看看MySQL的笔记
在Java中有这么一个定律:对象(Object)就是锁,前面内容涉及到的锁都是针对特定对象的(如表中的一行),对于某些更改没有特定对象,有没有一种锁针对这种场景呢?
谓词锁
谓词锁类似于共享/排它锁,但不属于特定的对象(例如,表中的一行),它属于所有符合某些搜索条件的对象,如:
1 | select * from bookings |
谓词锁限制访问:
🅰 如果事务A想要,读取匹配某些条件的对象,就像在这个 select 查询中那样,它必须获取查询条件上的共享谓词锁(shared-mode predicate lock)。如果另一个事务B,持有任何满足这一查询条件对象的排它锁,事务A必须等到B释放它的锁之后才允许进行查询
🅱 如果事务A想要,插入,更新或删除任何对象,则必须首先检查旧值或新值,是否与任何现有的谓词锁匹配。如果事务B持有匹配的谓词锁,那么A必须等到B已经提交或中止后才能继续
谓词锁的关键思想是,谓词锁甚至适用于数据库中尚不存在,但将来可能会添加的对象(幻象)。和快照隔离的区别在是:快照隔离中读不阻塞写,写不阻塞读;2PL中,写阻塞读,读阻塞写
索引范围锁
索引范围锁,也称为间隙锁(next-key locking)
谓词锁的弊端是性能不佳:如果活跃事务持有很多锁,检查匹配的锁会非常耗时。因此,大多数使用2PL的数据库实际上实现了索引范围锁,间隙锁是一种简化的近似版谓词锁
比如在房间预订数据库中,您可能会在room_id列上有一个索引,并且/或者在start_time 和 end_time上有索引(否则前面的查询在大型数据库上的速度会非常慢
🅰 假设您的索引位于room_id上,并且数据库使用此索引查找123号房间的现有预订。现在数据库可以简单地将共享锁附加到这个索引项上,指示事务已搜索123号房间用于预订
🅱 或者,如果数据库使用基于时间的索引来查找现有预订,那么它可以将共享锁附加到该索引中的一系列值,指示事务已经将12:00~13:00 时间段标记为用于预定
无论哪种方式,搜索条件的近似值都附加到其中一个索引上。现在,如果另一个事务想要插入,更新或删除同一个房间和/或重叠时间段的预订,则它将不得不更新索引的相同部分。在这样做的过程中,它会遇到共享锁,它将被迫等到锁被释放。这种方法能够有效防止幻读和写入偏差
序列化快照隔离(SSI)
可序列化快照隔离(SSI, serializable snapshot isolation) 它提供了完整的可序列化隔离级别,但与快照隔离相比只有只有很小的性能损失,是一种新的隔离技术
总结
1⃣ 脏读: 一个客户端读取到另一个客户端尚未提交的写入。读已提交或更强的隔离级别可以防止脏读
2⃣ 脏写: 一个客户端覆盖写入了另一个客户端尚未提交的写入。几乎所有的事务实现都可以防止脏写
3⃣ 读取偏差(不可重复读): 在同一个事务中,客户端在不同的时间点会看见数据库的不同状态。快照隔离经常用于解决这个问题,它允许事务,从一个特定时间点的一致性快照中读取数据。快照隔离通常使用多版本并发控制(MVCC) 来实现
4⃣ 更新丢失: 两个客户端同时执行读取-修改-写入序列。其中一个写操作,在没有合并另一个写入变更情况下,直接覆盖了另一个写操作的结果。所以导致数据丢失。快照隔离的一些实现可以自动防止这种异常,而另一些实现则需要手动锁定(select for update)
和脏写的区别在于:脏写是覆盖尚未提交的写入,更新丢失是覆盖了一个已提交的写入
5⃣ 写偏差: 一个事务读取一些东西,根据它所看到的值作出决定,并将决定写入数据库。但是,写的时候,决定的前提不再是真实的。只有可序列化的隔离才能防止这种异常
6⃣ 幻读 : 事务读取符合某些搜索条件的对象,另一个客户端进行写入,影响搜索结果。快照隔离可以防止直接的幻像读取,但是写入歪斜环境中的幻读需要特殊处理,例如索引范围锁定。只有可序列化的隔离才能防范所有这些问题。我们讨论了实现可序列化事务的三种不同方法:
- 字面意义上的串行执行: 如果每个事务的执行速度非常快,并且事务吞吐量足够低,足以在单个CPU核上处理,这是一个简单而有效的选择
- 两阶段锁定: 数十年来,两阶段锁定一直是实现可序列化的标准方式,但是许多应用出于性能问题的考虑避免使用它
- 可串行化快照隔离(SSI)
第9章节-一致性与共识
构建容错系统的最好方法,是找到一些带有实用保证的通用抽象,实现一次,然后让应用依赖这些保证。比如通过使用事务这个抽象,应用可以假装没有崩溃(原子性),没有其他人同时访问数据库(隔离性),存储设备是完全可靠的(持久性)。即使发生崩溃,竞态条件和磁盘故障,事务抽象隐藏了这些问题,因此应用不必担心它们
同样的分布式系统最重要的抽象之一就是共识(consensus):其非正式定义是让所有的节点对某件事达成一致
分布式一致性模型和事务的特性ACID中的一致性 ,隔离级别的区别❓
ACID一致性的概念是,对数据的一组特定陈述必须始终成立。即不变量(invariants)
分布式一致性主要是关于:面对延迟和故障时,如何协调副本间的状态
事务隔离的目的是为了,避免由于同时执行事务而导致的竞争状态
线性一致性
多数的数据库提供了最终一致性的保证(数据是最终收敛的)。最终一致性的问题是:如果你在同一个时刻问2个副本同样一个问题,可能得到不同的答案,线性一致性尝试提供只有一个副本的假象,即提供新鲜度保证(一个客户端完成写操作,所有client可以必须能看到最新的答案)
线性一致性和可序列化的区别❓
可序列化是事务的隔离性,它确保事务的执行是特定的顺序
线性一致性是读取和写入寄存器(单个对象)的新鲜度保证,它不会将多个操作组合为事务
一个数据库可以提供可串行性和线性一致性,这种组合称之为,单副本强可串行性(strong-1SR),基于2阶段锁的可串行化实现,通常是线性一致的,可重复读不是线性一致的
线性一致性的作用
🅰 单主复制的系统中,领导选取(只有一个节点持有锁)
🅱 唯一性约束(只有一个对象持有该id)
实现线性一致的系统
1⃣ 单主复制:可能线性一致
2⃣ 共识算法:线性一致
3⃣ 多主复制:非线性一致
CAP
有一种说法是: 一致性、可用性、分区容错性,三者只能选择其二,这种说法有一定的误导性。这里的P指的是网络分区13,网络分区是一种故障,是一定会(概率事件)存在的,P不是一个可选项而是一个必选项,那么就有了
🅰 CP : 在网络分区下一致但不可用 。若应用需要线性一致性,某些副本和其他副本断开连接,那么这些副本掉线时不能处理请求(单主复制+同步),请求必须等到网络问题解决,或直接返回错误。无论哪种方式,服务都不可用(unavailable)
🅱 AP : 在网络分区下可用但不一致 。应用不需要线性一致性,那么某个副本即使与其他副本断开连接,也可以独立处理请求(例如多主复制)。在这种情况下,应用可以在网络问题前保持可用,但其行为不是线性一致的
13:网络分区区别于分区,分区是一种中将数据集划分为多块,以此来提升并发读写能力; 而网络分区是指节点彼此断开但是仍然活跃。
全序 vs 偏序
因果顺序不是全序的
自然数集是全序的,如1,2,3;数学集合是偏序的,比如{a,b} 和 {b,c} 是没有办法比较大小的。线性一致是全序的,不存在任何并发,所有的操作在一条时间线上。而因果关系是偏序的,存在着并发,线性一致性强于因果一致性,但是性能不如因果一致性
序列号顺序
显示跟踪所有已读数据确保因果关系意味着巨大的额外开销,可以使用序列号或时间戳来排序事件,时间戳并不一定来自时钟,可以是一个逻辑时钟(自增计数器),单主复制的数据库中,主库为每个操作自增一个计数器,从库按照复制日志的顺序来应用写操作,那么从库的状态始终是因果一致的
非因果序列号生成器
对于无主复制或者多主复制,如何生成序列号呢?有下面三种方式:
1⃣ 每个节点生成自己独立的一组序列号,如有2个节点,一个奇数一个偶数
2⃣ 将物理时钟附加到每个操作上,也许可以提供一个全序关系
3⃣ 预先分配序列区块号,如节点A是1-1000区块的所有权;节点B是1001-2000区块的所有权
三种共同的问题是:生成的序列号与因果关系不一致。兰伯特时间戳可以产生与因果关系一致的时间戳
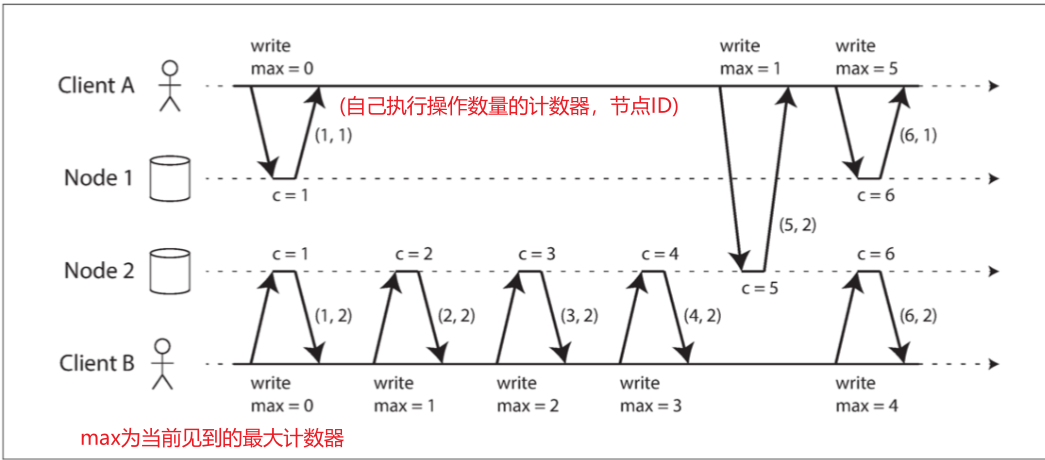
兰伯特时间戳
(计数器,节点ID)$(counter, node ID)$ 组成兰伯特时间戳,每个节点和每个客户端跟踪迄今为止所见到的最大计数器值,并在每个请求中包含这个最大计数器值。当一个节点收到最大计数器值大于自身计数器值的请求或响应时,它立即将自己的计数器设置为这个最大值。下面2条规则去判断:
🅰 如果你有两个时间戳,则计数器值大者是更大的时间戳
🅱 如果计数器值相同,则节点ID越大的,时间戳越大
todo
其中客户端 A 从节点2 接收计数器值 5 ,然后将最大值 5 发送到节点1 。此时,节点1 的计数器仅为 1 ,但是它立即前移至 5 ,所以下一个操作的计数器的值为 6 。虽然兰伯特时间戳定义了一个与因果一致的全序,但它还不足以解决分布式系统中的许多常见问题,比如确保用户名能唯一标识用户帐户的系统,你得搜集所有相同用户名的兰伯特时间戳,才能比较他们的时间戳,节点无法马上决定当前请求失败还是成功。所以仅知道全序是不够的,还需要知道全序何时结束
全序广播(原子广播)
全序广播通常被描述为在节点间交换消息的协议。 非正式地讲,它要满足两个安全属性:
1⃣ 可靠交付(reliable delivery): 没有消息丢失:如果消息被传递到一个节点,它将被传递到所有节点
2⃣ 全序交付(totally ordered delivery): 消息以相同的顺序传递给每个节点
正确的全序广播算法必须始终保证可靠性和有序性,即使节点或网络出现故障。当然在网络中断的时候,消息是传不出去的,但是算法可以不断重试,以便在网络最终修复时,消息能及时通过并送达
可以使用全序广播来实现可序列化的事务,由于具备上述2个安全属性,数据库的分区和副本就可以相互保持一致。节点得到了共识
🅰 全序广播等于共识
🅱 线性一致的CAS等于共识
分布式事务与共识
共识的目标只是让几个节点达成一致(get serveral nodes to agree on something)。节点达成一致(共识)的应用场景:
🅰 领导选取:如在单主复制中,如果有2个以上领导就会有发生脑裂情况,脑裂时2主都会接收写入,导致数据不一致或数据丢失
🅱 原子提交:在跨多节点或跨多分区事务的数据库中,所有节点必须就:一个事务是否成功这件事达成一致(要不都成功;要不都失败)
2PC是一个最简单的共识算法,更好的一致性算法比如ZooKeeper(Zab)和etcd(Raft)中使用的算法
区分普通事务和两种的不同的分布式事务
0⃣ 普通事务是相对单个节点而言的多对象操作;而分布式事务涉及多个节点
1⃣ 数据库内部的分布式事务, 一些分布式数据库(即在其标准配置中使用复制和分区的数据库)支持数据库节点之间的内部事务,比如MySQL Cluster的NDB存储引擎就有这样的内部事务支持。此情形下,所有参与事务的节点都运行相同的软件
2⃣ 异构分布式事务:在异构事务中,参与者是2者或者以上的技术,比如来自不同供应商的2个数据库/消息代理,跨系统的分布式事务需要保证原子提交
原子提交和2PC
对于多对象事务及维护次级索引的数据库,原子提交可以防止失败的事务搅乱数据库,避免数据库陷入半成品结果和半更新状态;对于单对象的原子性一般时都由数据库(存储引擎)本身保证。 两阶段提交(two-phase commit) 是一种用于实现跨多个节点的原子事务提交的算法,即确保所有节点提交或所有节点中止
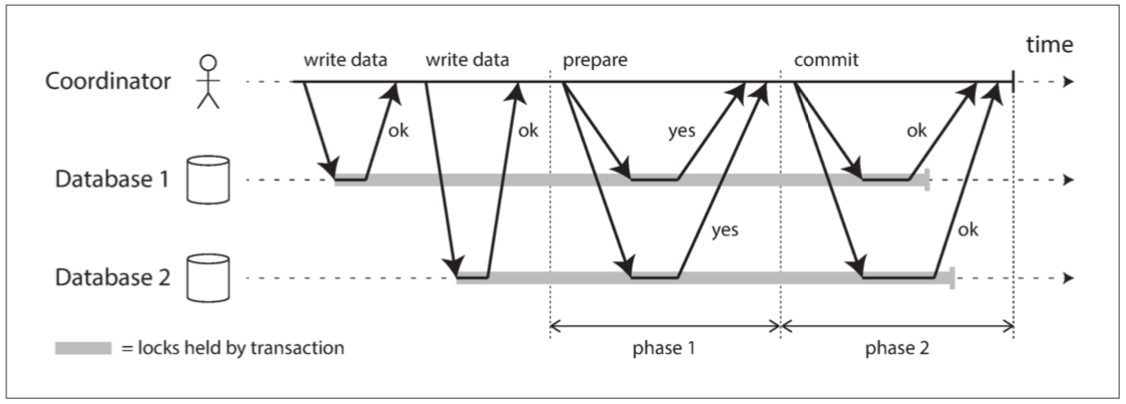
todo
2PC使用一个通常不会出现在单节点事务中的新组件:协调者(coordinator)(也称为事务管理器(transaction manager))。2PC事务以应用在多个数据库节点(参与者(participants))上读写数据开始。当应用准备提交时,协调者开始阶段1:它发送一个 准备(prepare) 请求到每个节点,询问它们是否能够提交,然后协调者会跟踪参与者的响应:
- 如果所有参与者都回答“是”,表示它们已经准备好提交,那么协调者在阶段2发出 提交(commit) 请求,然后提交真正发生
- 如果任意一个参与者回复了“否”,则协调者在阶段2 中向所有节点发送 中止(abort) 请求
2PC具体的流程如下:
1⃣ 当应用想要启动一个分布式事务时,它向协调者请求一个事务ID。此事务ID是全局唯一的
2⃣ 应用在每个参与者上启动单节点事务,并在单节点事务上捎带上这个全局事务ID
3⃣ 当应用准备提交时,协调者向所有参与者发送一个准备请求,并打上全局事务ID的标记。如果任意一个请求失败或超时,则协调者向所有参与者发送针对该事务ID的中止请求
4⃣ 参与者收到准备请求时,需要确保在任意情况下都可以提交事务。这包括将所有事务数据写入磁盘(出现故障,电源故障,或硬盘空间不足都不能是稍后拒绝提交的理由)以及检查是否存在任何冲突或违反约束。通过向协调者回答“是”,节点承诺,只要请求,这个事务一定可以不出差错地提交。换句话说,参与者放弃了中止事务的权利,但没有实际提交
5⃣ 当协调者收到所有准备请求的答复时,会就提交或中止事务作出明确的决定(只有在所有参与者投赞成票的情况下才会提交)。协调者必须把这个决定写到磁盘上的事务日志中,如果它随后就崩溃,恢复后也能知道自己所做的决定。这被称为提交点(commit point)
6⃣一旦协调者的决定落盘,提交或放弃请求会发送给所有参与者。如果这个请求失败或超时,协调者必须永远保持重试,直到成功为止。没有回头路:如果已经做出决定,不管需要多少次重试它都必须被执行。如果参与者在此期间崩溃,事务将在其恢复后提交——由于参与者投了赞成,因此恢复后它不能拒绝提交
下图是MySQL的两阶段提交过程,该过程保证bin-log和redo-log一致
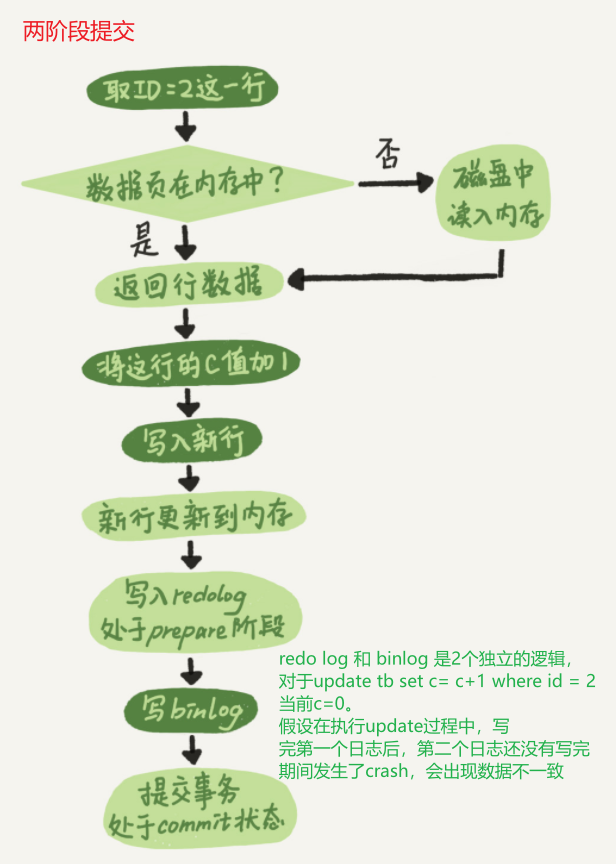
todo
协调者失效
上述第3⃣步中很协调者发送“准备”请求之前失败,参与者可以安全的终止事务;在第5⃣ 步中如果任何提交和终止请求失败,协调者将无条件重试,但是协调者崩溃,参与者就什么也做不了只能等待。参与者的这这种事务状态称为:存疑或者不确定
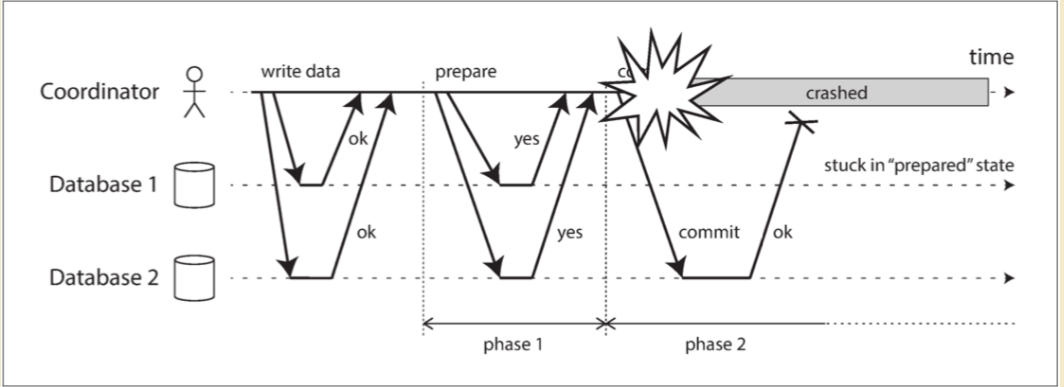
todo
上图中:协调者实际上决定提交,数据库2收到提交请求,但是协调者在将提交请求发送到数据库1之前发生崩溃,因此数据库1不知道是否提交或中止。这里即便超时, 也是没用的:
- 如果数据库1 在超时后单方面中止,它将最终与执行提交的数据库2 不一致
- 单方面提交也是不安全的,因为另一个参与者可能已经中止了
此时完成2PC的唯一方法是等待协调者恢复,因此,协调者必须在向参与者发送提交/中止请求之前,将其提交/中止决定写入磁盘上的事务日志,协调者恢复后,通过读取其事务日志来确定所有存疑事务的状态,任何在协调者日志中没有提交记录的事务都会中止
恰好一次的消息处理
异构的分布式事务能够集成两种不同的系统,比如当用于处理消息的数据库事务成功提交后,消息队列中的一条消息可以被认为已处理。如果消息或者数据库事务任意一个失败,2者都会终止,而消息代理可能会在稍后安全的重传消息。通过这种方式,可以确保消息被有效地恰好处理一次
XA事务
扩展架构(eXtended Architecture)是跨异构技术实现两阶段提交的标准。许多关系型数据库(PostgresSQL、MySQL、SQL Server、Oracle))和消息代理(ActiveMQ,HornetQ,MSMQ和IBM MQ)都支持XA
容错共识
共识的定义:一个或多个节点可以提议(propose)某些值,而共识算法决定(decides)采用其中的某个值
共识算法需要满足以下性质:
1⃣ 一致同意:没有2个节点的决定不同
2⃣ 完整性:没有节点决定2次
3⃣ 有效性:如果一个节点决定了值
v,则v由某个节点所提议4⃣ 终止 : 由所有未崩溃的节点来最终决定值
终止属性形成了容错的思想,该属性是一个活性属性,而另外三个是安全属性。如果不关心容错,仅仅满足前三个属性就OK,因为你可以将其中一个节点硬编码为leader,让该节点做出所有的决定,但是节点一旦失效,系统无法就无法做出决定了。比如2PC就能够满足,但是2PC的问题是,协调者失效,存疑的参与者无法决定是提交还是终止,故2PC不满足终止属性的要求
绝大多数共识算法实际上并不直接使用1⃣2⃣3⃣4⃣形式化模型,而是使用全序广播代为实现
共识算法和全序广播
最著名的容错共识算法是视图戳复制(VSR, viewstamped replication),Paxos,Raft 以及 Zab。视图戳复制,Raft和Zab直接实现了全序广播,因为这样做比重复 一次一值(one value a time) 的共识更高效,因为全序广播的要求是:
1⃣ 可靠交付(reliable delivery): 没有消息丢失:如果消息被传递到一个节点,它将被传递到所有节点
2⃣ 全序交付(totally ordered delivery): 消息以相同的顺序传递给每个节点
可以发现,全序广播等于进行了重复多轮共识
在单主复制中,将所有的写入操作都交给主库,并以相同的顺序将他们应用到从库,从而使副本保持在最新状态,这里其实是一种 “独裁类型” 的共识算法,领导者是运维指定的,一旦故障必须人为干预,它无法满足共识算法的终止属性
时代编号和法定人数
共识协议一般会定义1个时代编号(epoch number),在Paxos中称为投票编号(ballot number),视图戳复制中的视图编号(view number),以及Raft中的任期号码(term number),并确保在每个时代中,领导者都是唯一的。每次领导者被认为挂掉的时候,会产生全序且单调递增的新的时代编号,更高时代编号的领导才真的领导。节点在做出决定之前对提议进行投票的过程是一种同步复制,这是共识的局限性
总结:
很多问题都可以归结为共识问题,并且彼此等价(从这个意义上来讲,如果你有其中之一的解决方案,就可以轻易将它转换为其他问题的解决方案)。这些等价的问题包括:
1⃣ 线性一致性的CAS寄存器: 寄存器需要基于当前值是否等于操作给出的参数,原子地决定是否设置新值
2⃣ 原子事务提交 : 数据库必须决定是否提交或中止分布式事务
3⃣ 全序广播: 消息系统必须决定传递消息的顺序
4⃣ 锁和租约: 当几个客户端争抢锁或租约时,由锁来决定哪个客户端成功获得锁
5⃣ 成员/协调服务: 给定某种故障检测器(例如超时),系统必须决定哪些节点活着,哪些节点因为会话超时需要被宣告死亡
6⃣ 唯一性约束: 当多个事务同时尝试使用相同的键创建冲突记录时,约束必须决定哪一个被允许,哪些因为违反约束而失败
如果你只有一个节点,或者你愿意将决策权分配给单个节点,所有这些事都很简单。这就是在单领导者数据库中发生的事情:所有决策权归属于领导者,这就是为什么这样的数据库能够提供线性一致的操作,唯一性约束,完全有序的复制日志等。但如果该领导者失效,或者如果网络中断导致领导者不可达,这样的系统就无法取得任何进展。应对这种情况可以有三种方法:
1⃣等待领导者恢复,接受系统将在这段时间阻塞的事实。许多XA/JTA事务协调者选择这个选项。这种方法并不能完全达成共识,因为它不能满足终止属性的要求:如果领导者续命失败,系统可能会永久阻塞
2⃣ 人工故障切换,让人类选择一个新的领导者节点,并重新配置系统使之生效,许多关系型数据库都采用这种方方式。这是一种来自“天意”的共识 —— 由计算机系统之外的运维人员做出决定。故障切换的速度受到人类行动速度的限制,通常要比计算机慢得多
3⃣ 使用算法自动选择一个新的领导者。这种方法需要一种共识算法,使用成熟的算法来正确处理恶劣的网络条件是明智之举
批处理
关于衍生数据
第三部分的内容,主要讨论将多个不同数据系统(有着不同的数据模型,并针对不同的访问模式进行优化)集成为一个协调一致的应用架构时,会遇到的问题。从高层次看,存储和记录数据系统分为2大类:
🅰 记录系统(System of record) :数据的权威版本(如果其他系统和记录系统之间存在任何差异,那么记录系统中的值是正确的)
🅱 衍生数据系统(Derived data systems) :通常是另一个系统中的现有数据进行转换或处理的结果,如缓存、索引、物化视图等,推荐系统中,预测汇总数据通常衍生自用户日志
三种不同的数据处理系统:
1⃣ 服务(在线系统)
2⃣ 批处理系统(离线系统)
3⃣ 流处理系统(准实时系统)
流处理和批处理最关键的区别是处理无界数据和有界数据
MPP数据库(大规模并行处理(MPP, massively parallel processing)专注于在一组机器上并行执行分析SQL查询,而MapReduce和分布式文件系统的组合则更像是一个可以运行任意程序的通用操作系统,批处理框架看起来越来越像MPP数据库了
UNIX
基于Unix的awk,sed,grep,sort,uniq和xargs等工具的组合,可以轻松的帮助我们完成一些数据分析的工作,而且性能相当的好。而且,这些工具使用相同的接口,在Unix中,这种接口是一个file(准确的说是一个文件描述符)
文件是一个统一的接口,如果我们的程序的输入和输出都是文件,那么所有的程序缝合起来,像接力一样完成复杂的工作;统一的接口还包括URL和HTTP(我们可以在网站和网站之间无缝跳转)。这和函数式编程的理念非常类似
Unix工具很强大,但是其局限性就是只能在一台机器上运行,所以Hadoop这样的工具应运而生
MapReduce
Unix和MapReduce比对
| MR | 除了生成输出没有副作用 | 简单粗暴却有效 | 分布式 | 分布式文件系统上读写文件 | 使用无共享架构 | 通过工作流(workflow)将多个MR作业连接在一起,文件 |
|---|---|---|---|---|---|---|
| Unix | 除了生成输出没有副作用 | 简单粗暴却有效 | 单机 | 使用stdin和stdout作为输入输出 |
共享架构 | 管道符,内存缓存区17 |
17:多个MR任务连接的方式是将后一个MR任务的输入配置为前一个MR任务的输出;而Unix命令管道是直接将一个进程的输出作为另外一个进程的输入,仅用一个很小的内存缓冲区
MapReduce是一个编程框架,可以使用它编写代码处理HDFS等分布式文件系统中的大型数据集,并且遵循移动计算大于移动数据的原则。MapReduce的数据处理过程如下:
1⃣ 读取一组输入文件,并将其分解成记录(records)
2⃣ 调用Mapper函数,从每条输入记录中提取一对键值;map的任务数由输入文件块的数量决定
3⃣ 按键排序所有的键值对
4⃣ 调用Reducer函数遍历排序后的键值对,相同的key,将会在reducer中相邻;reduce的任务数量是可配置的
其中第2⃣4⃣步是自定义数据处理代码的地方,第3⃣步Mapper的输出始终在送往Reducer之前进行排序,无须编写。下图是个三个Mapper和三个Reducer的MR任务:
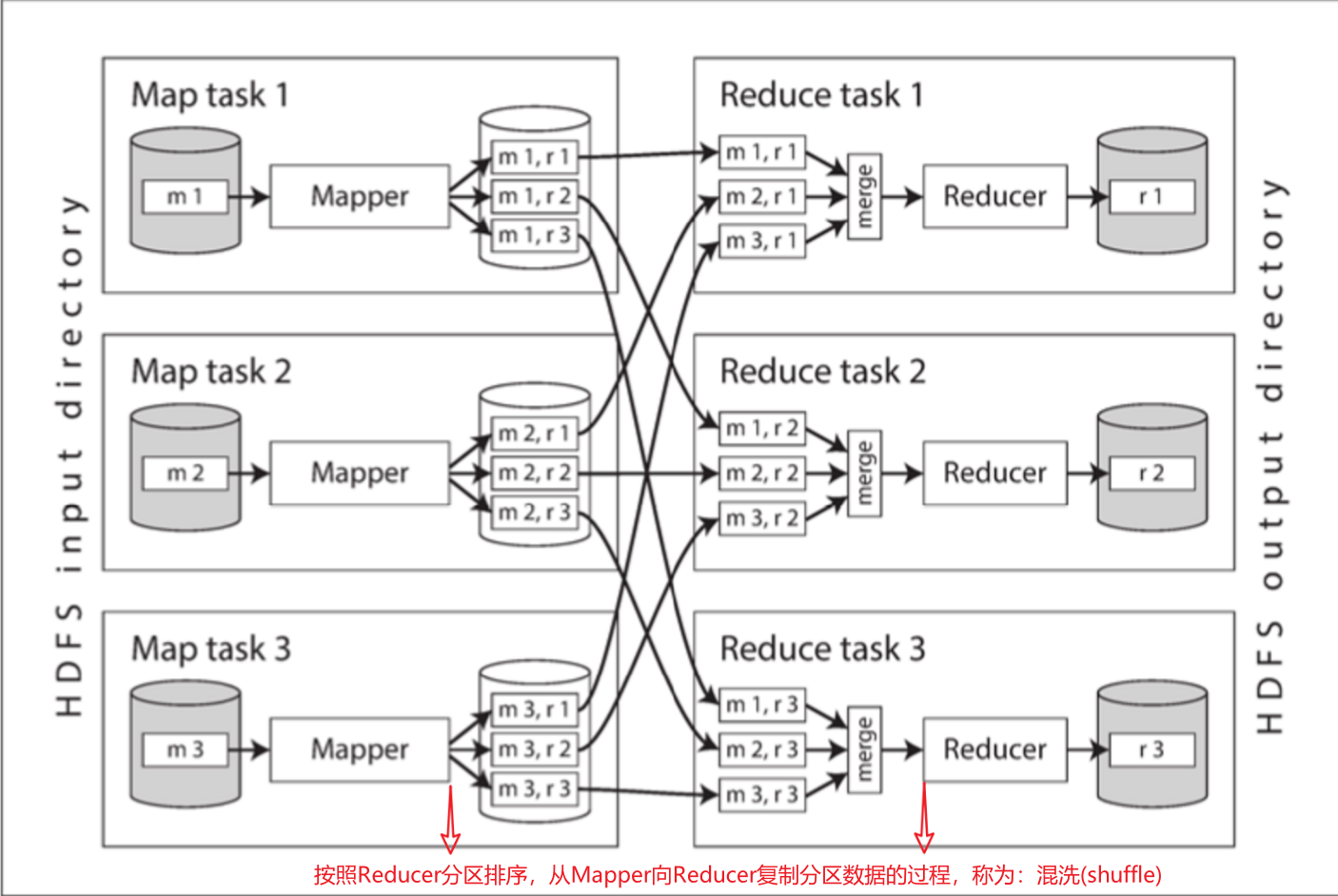
todo
Mapper中的数据去往Reducer的过程可以看做是Mapper将消息发送给Reducer,每当Mapper发出一个键值对,这个键的作用就好像是去往到目标地址(IP地址)
Reducer端联接:
如下图,左侧是事件日志,右侧是用户数据库,任务需要将用户活动和用户档案相关联:

todo
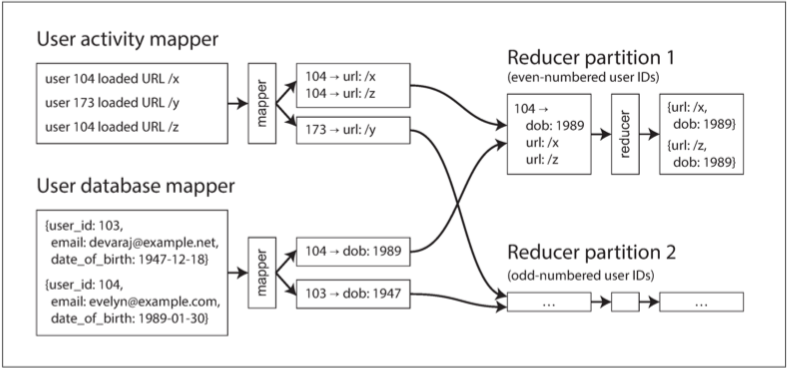
todo
处理模型多样性[^19] | 针对故障频繁而设计[^21] | | 分布式数据库 | 要求特定的模型(关系/文档) | SQL模型[^20] | 查询失效时,多数MPP会终止查询 | > [^19]: 并非所有数据类型的处理都可以合理的用SQL表达(推进系统、特征工程等),所以编写代码是必须的,而MR能使得工程师可以轻松的在大型数据集上执行自己的代码,甚至还可以基于MapReduce+HDFS 建立SQL查询执行引擎,比如Hive就是这么做的;除了SQL和MapReduce之外,由于Hadoop平台的开放性,还可以构建更多的模型。由于不需要将数据导入到专门的系统进行不同类型的处理,采用新的处理模型也更容易。如MPP风格的分析型数据库impala,随机访问风格的OLTP数据库HBase(LSM) >[^20]: MPP 是单体的紧密集成的软件,负责磁盘上的存储布局,查询计划,调度和执行,这些组件针对数据库的特定需求做了优化,因此可以对特定查询有很好的性能,但只支持SQL模型 > [^21]: 落盘一方面是容错,一方面是假设数据集太大不能适应内存。并且支持支持资源的过度使用 💔:使用原始的`MapReduce API`来实现复杂的处理工作实际上是非常困难,所以在MapReduce上有很多高级编程模型(Pig,Hive,Cascading,Crunch)被创造出来。🅰方面,MapReduce非常稳健;🅱方面,对于某些类型的处理而言,其他工具有时会快上几个数量级。流处理组件(storm、spark、flink)可以认为是解决"慢"这个问题而被发展出来的,物化中间状态也是一种加速方式 ## 物化中间状态 将数据发布到分布式文件系统中众所周知的位置能够带来**松耦合**,这样作业就不需要知道是谁在提供输入或谁在消费输出,一个作业的输出只能用作另一个作业的输入的情况下,分布式文件系统上的文件只是简单的**中间状态(intermediate state)**:一种将数据从一个作业传递到下一个作业的方式。将这个中间状态写入文件的过程称为**物化(materialization)**[^22][^23] > [22]:物化:意味着对某个操作的结果立即求值并写出来,而不是在请求时按需计算 > [23]:关于物化视图和视图的区别:物化视图基于磁盘,并且基于查询定期更新;视图是虚拟表,每次查询查询的是虚拟表 > > link: https://en.wikipedia.org/wiki/Materialized_view + https://stackoverflow.com/questions/93539/what-is-the-difference-between-views-and-materialized-views-in-oracle + https://en.wikipedia.org/wiki/Materialized_view 💔:Unix管道将一个命令的输出与另一个命令的输入连接起来。管道并没有完全物化中间状态,而是只使用一个小的内存缓冲区,将输出增量地**流(stream)**向输入,与Unix管道相比,MapReduce完全物化中间状态的方法的不足之处在于: 1⃣MapReduce作业只有在前驱作业(生成其输入)中的所有任务都完成时才能启动,而由Unix管道连接的进程会同时启动,输出一旦生成就会被消费 2⃣ Mapper通常是多余的,如果Reducer和Mapper的输出有着相同的分区与排序方式,那么Reducer就可以直接串在一起,而不用与Mapper相互交织 3⃣ 将中间状态存储在分布式文件系统中意味着这些文件被复制到多个节点 ## 数据流引擎 为了解决MapReduce的这些问题,几种用于分布式批处理的新执行引擎(Spark、Tez、Flink)被开发出来,它们的设计方式有很多区别,但有一个共同点:把整个工作流作为单个作业来处理,而不是把它分解为独立的子作业。由于它们将工作流显式建模为数据从几个处理阶段穿过,所以这些系统被称为**数据流引擎(dataflow engines)**,像MapReduce一样,它们在一条线上通过反复调用用户定义的函数来一次处理一条记录,这些函数为**算子(operators)**,数据流引擎提供了几种不同的选项来将一个算子的输出连接到另一个算子的输入: - 一种选项是对记录按键重新分区并排序,就像在MapReduce的混洗阶段一样。这种功能可以用于实现排序合并连接和分组 - 另一种可能是接受多个输入,并以相同的方式进行分区,但跳过排序。当记录的分区重要但顺序无关紧要时,这省去了分区散列连接的工作,因为构建散列表还是会把顺序随机打乱 - 对于广播散列连接,可以将一个算子的输出,发送到连接算子的所有分区 与MapReduce模型相比,它有几个优点: 1⃣排序等昂贵的工作只需要在实际需要的地方执行,而不是默认地在每个Map和Reduce阶段之间出现 2⃣没有不必要的Map任务,因为Mapper所做的工作通常可以合并到前面的Reduce算子中(因为Mapper不会更改数据集的分区) 3⃣由于工作流中的所有连接和数据依赖都是显式声明的,因此调度程序能够总览全局,知道哪里需要哪些数据,因而能够利用局部性进行优化。例如,它可以尝试将消费某些数据的任务放在与生成这些数据的任务相同的机器上,从而数据可以通过共享内存缓冲区传输,而不必通过网络复制 4⃣通常,算子间的中间状态足以保存在内存中或写入本地磁盘,这比写入HDFS需要更少的I/O(必须将其复制到多台机器,并将每个副本写入磁盘)。 MapReduce已经对Mapper的输出做了这种优化,但数据流引擎将这种思想推广至所有的中间状态 5⃣ 算子可以在输入就绪后立即开始执行;后续阶段无需等待前驱阶段整个完成后再开始 6⃣ 与MapReduce(为每个任务启动一个新的JVM)相比,现有Java虚拟机(JVM)进程可以重用来运行新算子,从而减少启动开销 你可以使用数据流引擎执行与MapReduce工作流同样的计算,而且由于此处所述的优化,通常执行速度要明显快得多。相同的处理逻辑,可以通过修改配置切换底层计算引擎,简单地从MapReduce切换到Tez或Spark[^24] > [^24]:Tez是一个相当薄的库,它依赖于YARN shuffle服务来实现节点间数据的实际复制,而Spark和Flink则是包含了独立网络通信层,调度器,及用户向API的大型框架 ## 总结 本章主要讲述了Unix的管道思想,MapReduce与其接口HDFS,最后是数据流引擎构建自己的管道式的数据传输机制。并且还讨论了分布式批处理框架要解决的2个主要问题: 🅰 分区:这一过程的目的是把所有的**相关**数据(例如带有相同键的所有记录)都放在同一个地方 🅱容错:MapReduce经常写入磁盘,这使得从单个失败的任务恢复很轻松,无需重新启动整个作业,但在无故障的情况下减慢了执行速度。数据流引擎更多地将中间状态保存在内存中,更少地物化中间状态,这意味着如果节点发生故障,则需要重算更多的数据。确定性算子减少了需要重算的数据量 # 流处理 流处理和批处理最原始的区别在于,流处理处理无界数据,而批处理针对有界数据。在流处理中的上下文中,记录通常被叫做**事件**,一个事件由生产者(producer)/发布者(publisher)/发送者(sender)生成一次,然后可能由多个消费者(consumer)/订阅者(subscribers)/接收者(recipients)进行处理。流处理的目标是**事件发生后,立刻得到处理**。流处理中相关的事件通常被聚合为一个主题(topic)或流(stream) 本质上来说,文件或者是数据库可以连接生产者和消费者,但是这种方式下消费者需要不断降低轮询文件/数据库的间隔,才能降低事件处理的延迟,而轮询会增加数据库的额外开销,我们希望在有新的事件产生的时候,能够通知到消费者,数据库的触发器或许是一个可选项,但是触发器功能有限,为了解决这个问题,消息系统应运而生 > 2个进程之间进行消息传递(通信),可以通过接口调用,还可以使用消息服务 ## 消息系统 消息系统一定要考虑2个问题: 🅰生产者发送消息的速度比消费者能够处理的速度快该如何应对?有三种方式处理: * 1⃣丢掉消息 * 2⃣将消息放入缓冲队列 * 3⃣ 背压机制(backpressure)/流量控制(flow control):即为阻塞生产者,避免其发送更多的消息[^14] > [^14]: 比如能够恰好连接1个生产者和一个消费者Unix管道和TCP连接,他们在应对这个问题的时候使用背压机制,它们有一个固定大小的缓冲区,一旦填满发送者就会被阻塞,直到接受者从缓冲区取出数据 🅱 如果节点崩溃或短暂脱机,是否会有消息丢失?也即**持久性**要求 批处理的一个优良的特性是,它提供了强大的可靠性保证:失败的任务会自动重试,且失败任务的输出会自动丢弃。这意味着好像故障没有发生一样,我们尝试⚠*在流处理中达到类似的保证*。有些消息系统是直连生产者和消费者,比如使用UDP连接的应用,这种方式的确latency很低,但此类应用有一个前提假设:消费者和生产者始终在线,流处理如果是用这种方式,消费者一旦脱机,可能会丢失期间的消息 **消息代理/消息队列** 本质上消息代理是**针对处理消息流**的数据库。消息代理解决了上文提及的2个问题: 🅰 (消费者)消费能力不足时,暂存消息;不需要丢弃消息或者背压 🅱 持久性保证:落盘 | 消息代理 | 消息*成功*传递给消费者后,自动删除 | 基于主题的模式匹配 | 不支持任意查询,数据变化时,会通知消费者 | | -------- | ---------------------------------- | ------------------ | ---------------------------------------- | | 数据库 | 数据库保留数据直到显示删除 | 数据库支持二级索引 | 查询时,往往是基于某个时间点的快照 | 如上描述的,消息队列和常规的数据的差别,其中行1是关于消息代理的传统观点,被封装在JMS/AMQP[^15]标准中,其实现有RabbitMQ,ActiveMQ等 > [^15]: JMS: Java Message Service,是关于Java消息中间的一组接口标准,所有消息中间件(MOM)需要实现这组接口,可类比JDBC > > AMQP: Advanced Message Queuing Protocol 高级消息队列协议:面向消息中间件提供的开放的应用层协定 消息代理中,如果有多个消费者读取同一个主题的消息时,使用2种主要的消息传递模式: 🅰 负载均衡(load balance) : 在消费者间共享消费主题 🅱 扇出(fan-out) : 将每条消息传递给多个消费者 两种模式可以组合使用:两个独立的消费者组可以每组各订阅一个主题,每一组都共同收到所有消息,但在每一组内部,每条消息仅由单个节点处理
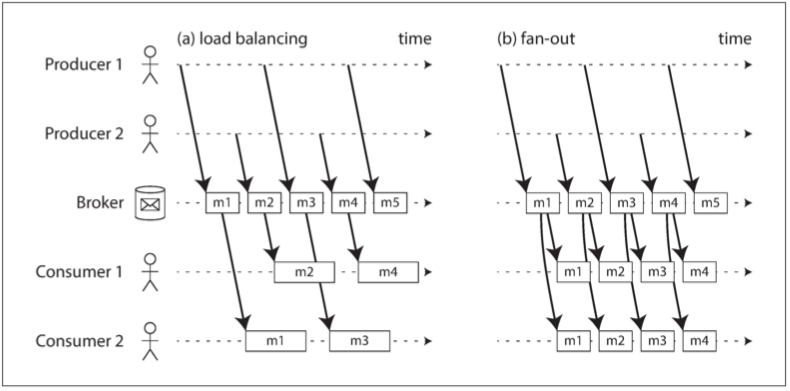
todo
消息代理使用确认(acknowledgment)16机制,来确保消息不会丢失,但一种可能的情况是:代理向消费者传递消息后消费者崩溃或处理了部分崩溃了,代理由于超出一段时间没有收到确认(也可能是确认在网络中丢失了),便将消息传递给另外一个消费者,当消费者的消费模式是负载均衡时,下面的情况可能会发生:处理m3时消费者2崩溃,因此稍后重传至消费者1
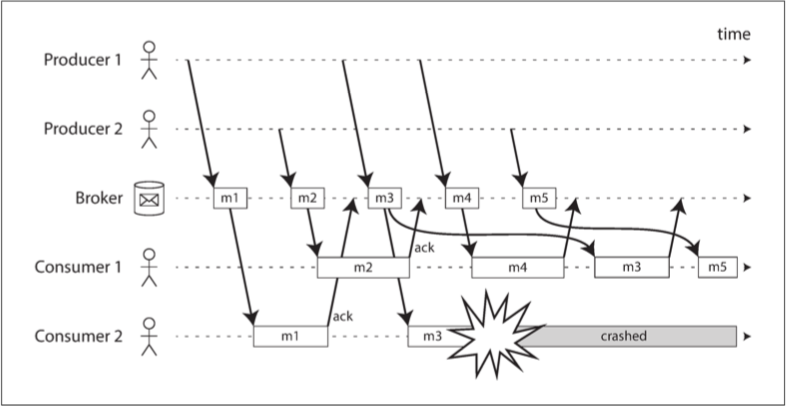
todo
16. 确认机制:消费者必须显示的告知代理处理完毕的时间,以便代理将消息从队列中移除 ↩
批处理的关键特性是:重试失败任务不会发生任何副作用,而AMQP/JMS风格的消息传递收到消息是具有破坏性的,因为确认可能导致消息从代理中被删除,因此再次运行同一个消费者可能会得到不同的结果。即便是注册新的消费者到消息系统,通常只能接收到消费者注册之后开始发送的消息,而文件系统/数据库系统新增的客户端能够读取到任意久远的数据
基于日志的消息代理(log-based message brokers) 尝试实现 🅰既有数据库的持久存储方式;🅱又有消息传递的低延迟通知
基于日志的消息代理
在基于日志(append only mode)的消息代理中,生产者通过将消息追加到日志末尾来发送消息,而消费者通过依次读取日志来接收消息,若消费者读到日志末尾,则会等待新消息追加的通知(如Unix的 tail -f)。同时为了提升吞吐量,基于日志的消息代理可以对日志进行分区,每个分区内,代理为每个消息分配一个单调递增的序列号/偏移量(offset)。并且分区内消息完全有序(跨分区无顺序保证)
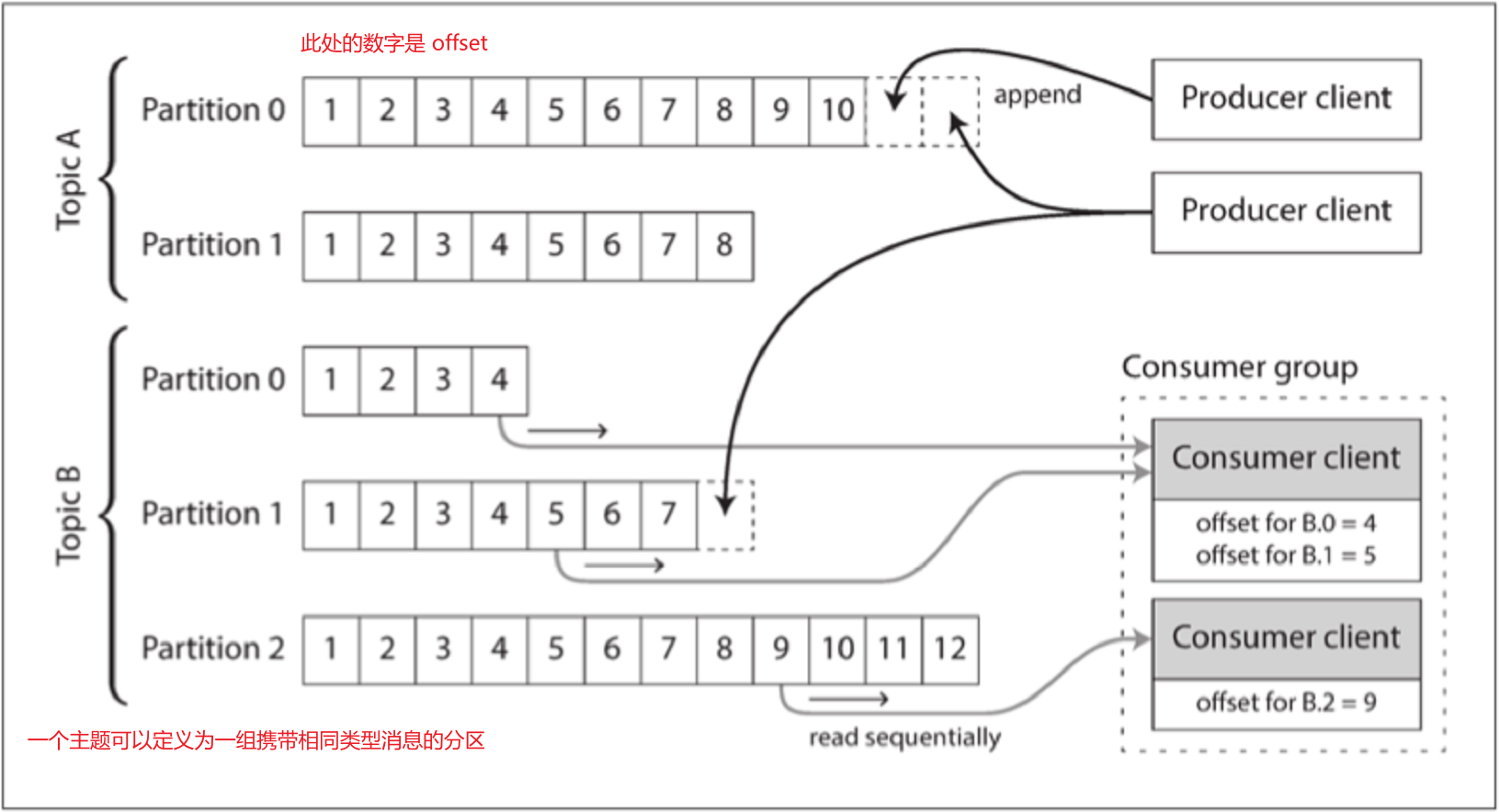
todo
Apache Kafka、Amazon Kinesis Streams、Twitter的DistributedLog都是基于日志的消息代理。其中下面几点要注意:
1⃣消费者组:支持多个消费者组成一个消费者主订阅一个主题,单个节点消费特定的分区,一般而言单线程处理单分区是更适合的选择,通过增加分区的方式提高并行度
2⃣ 消费者偏移量:所有偏移量小于消费者的当前偏移量的消息已经被处理(类似单主复制中的日志序列号)25
25. ❓消费者节点失效,则失效消费者的分区将指派给其他节点,并从最后记录的偏移量开始消费消息。如果消费者已经处理了后续的消息,但还没有记录它们的偏移量,那么重启后这些消息将被处理两次,这个问题如何解决呢? ↩
3⃣重播旧消息:消费者的消费唯一的副作用就是导致偏移量的前进,但是消费者可以操纵偏移量(类似于批处理)
流和数据库
此间的讨论,我们发现基于日志的消息代理从数据库中获得灵感并将其应用于消息传递,其实也可以反过来,从消息传递和流中获得灵感,并将他们应用于数据库。在单主复制中,主库的写入事件构成写入流,将写入流应用到从库,最终得到数据的精确副本。在异构数据系统中,由于相同或相关的数据出现在了不同的地方,因此相互间需要保持同步:如果某个项目在数据库中被更新,它也应当在缓存,搜索索引和数据仓库(使用ETL)中被更新,我们在批处理将描述了如何使用批处理去更新其他衍生数据系统。使用的批处理的弊端是时延,如何保证衍生数据系统低延迟获取记录系统的变更数据?
这就涉及到变更数据捕获(change data capture, CDC),这是一种观察写入数据库的所有数据变更,并将其提取并转换为可以复制到其他系统中的形式的过程。如下图:捕获数据库中的变更,并不断将相同的变更应用至搜索索引
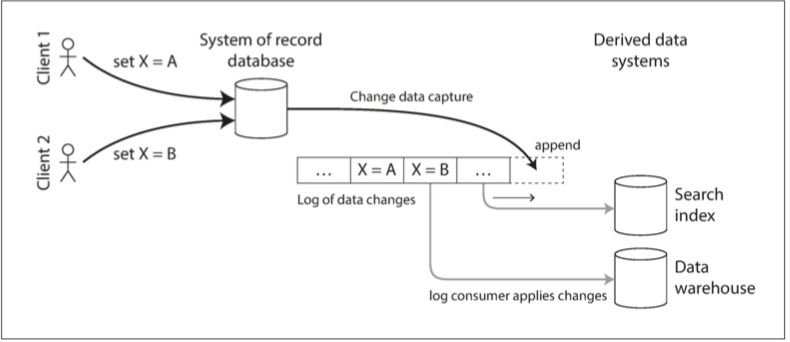
todo
todo
🅱 事件时间:事件发生的时间。延迟先发生的事件先到达处理节点,无法确定是否已经收到了特定窗口的所有事件,如何处理这种在窗口宣告完成之后到达的滞留(straggler)事件?
窗口
1⃣ 滚动窗口(Tumbling Window):窗口有固定的长度,而且每个事件都只属于一个窗口
2⃣跳动窗口(Hopping Window) :窗口有固定的长度,如1分钟跳跃步长的5分钟窗口
3⃣滑动窗口(Sliding Window):滑动窗口包含了彼此间距在特定时长内的所有事件,通过维护一个按时间排序的事件缓冲区,并不断从窗口中移除过期的旧事件,可以实现滑动窗口
4⃣会话窗口(Session window) 将同一用户出现时间相近的所有事件分组在一起,而当用户一段时间没有活动时(例如,如果30分钟内没有事件)窗口结束
流式连接
涉及流-流连接,流-表连接,与表-表连接
1⃣ 流流连接,实际是窗口的连接,Window join 作用在两个流中有相同 key 且处于相同窗口的元素上。比如Flink将流流连接细分为滚动Window Join,滑动Window Join,会话Window Join。Flink的双流Join。比如下图是Spark Streaming中一个广告流和一个点击流的连接
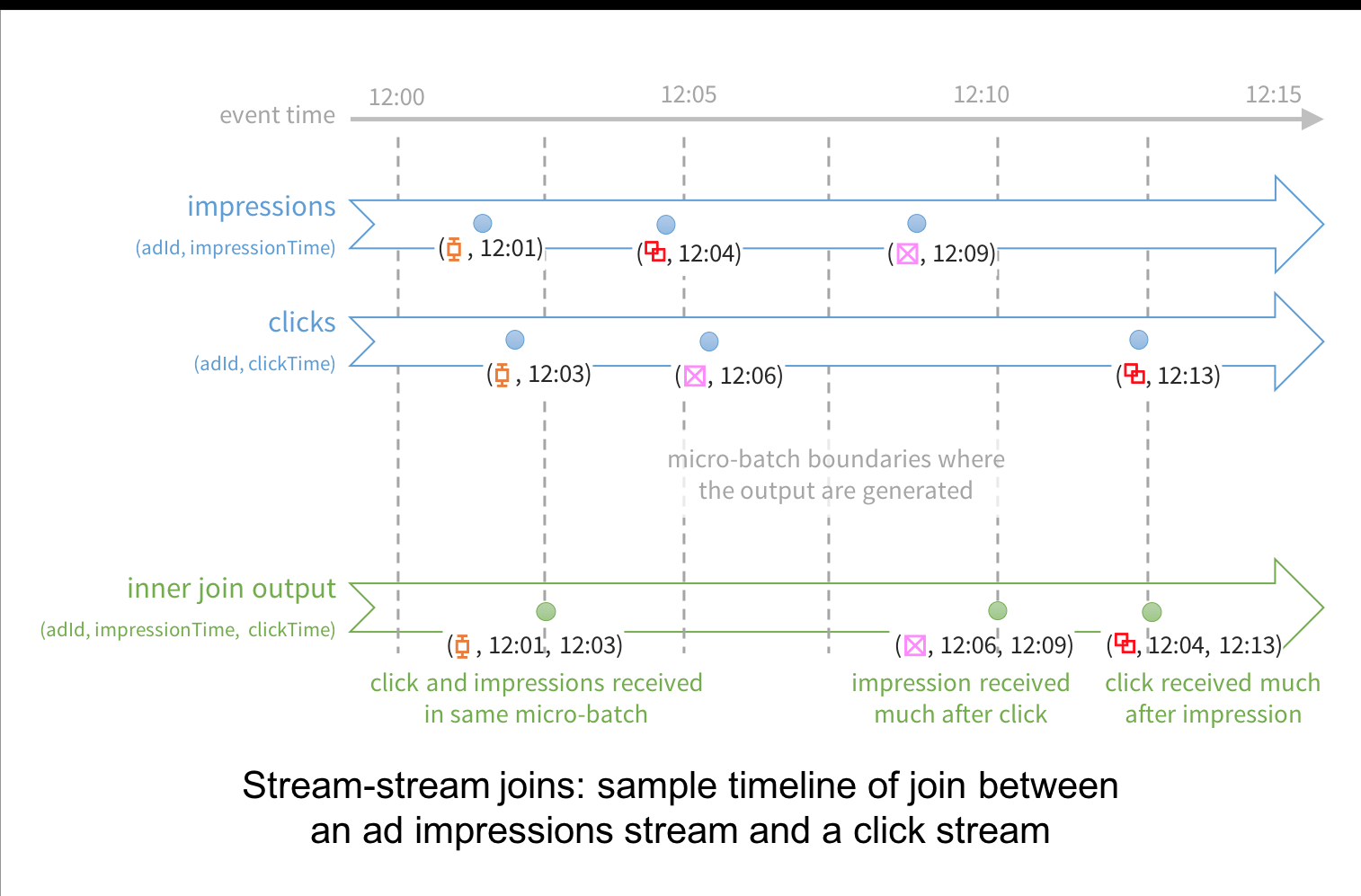
todo
2⃣流表连接,实际是流扩展。如下图的点击流和用户档案的连接,首先将数据库副本加载到流处理器中,然后流处理器需要一次处理一个活动事件。 流表连接实际上非常类似于流流连接;最大的区别在于对于表的变更日志流,连接使用了一个可以回溯到“时间起点”的窗口
todo
3⃣ 表表连接。在推特时间线的例子中,用户查看自身主页时间线时,迭代用户所关注人群的推文并合并它们需要一个时间线缓存,在流处理器中实现这种缓存维护,需要推文事件流(发送与删除)和关注关系事件流(关注与取消关注),即该流处理的过程是维护了一个连接了两个表(推文与关注)的物化视图,如下时间线实际上是这个查询结果的缓存,每当基础表发生变化时都会更新
1 | select follows.follower_id as timeline_id, |
连接的时间依赖性
流流、流表、表表连接有很多共同点,他们都需流处理器维护连接一侧的一些状态(广告流和点击流,用户档案,关注列表),然后当连接另外一侧的消息到达时查询该状态。这里会有一个问题,如在流表连接的例子中,如果用户更新了档案,哪些活动事件与旧档案连接(在档案更新前)?,哪些又与新档案连接(在档案更新后)?即连接存在时序依赖,比如处理发票和税率问题时,当连接销售额与税率表时,你可能期望的是使用销售时的税率参与连接,如果你正在重新处理历史数据,销售时的税率可能和现在的税率有所不同
即如果跨流事件的顺序是未定的,则连接会变成不确定性的,那么在同样输入上重跑可能会得到不同的结果。这个问题在数仓中叫缓慢变化的维度(slowly changing dimension,SCD)31,通常通过对特定版本的记录使用唯一的标识符来解决:例如,每当税率改变时都会获得一个新的标识符,而发票在销售时会带有税率的标识符。这种变化使连接变为确定性的,但也会导致日志压缩无法进行:表中所有的记录版本都需要保留
31. SCD,处理SCD问题有很多种方式,从SCD0到SCD6,其中最流行的是:SCD1和SCD2;wiki:https://en.wikipedia.org/wiki/Slowly_changing_dimension;YouTube tutorial:https://www.youtube.com/watch?v=XqdZF0DJpUs ↩
流处理如何处理容错
在批处理中,容错的方式就是重跑,而且其输出的效果就像只处理了一次一样,这个原则叫做恰好/精确一次语义(exactly-once semantics),流处理为了实现恰好一次语义,有以下2种方式
🅰 微批,即将流分解成小块,并像微型批处理一样处理每个块,微批次(通常为1S)也隐式提供了一个与批次大小相等的滚动窗口(按处理时间而不是事件时间戳分窗),代表应用为Spark Streaming
🅱存档点, Apache Flink会定期生成状态的滚动存档点并将其写入持久存储。如果流算子崩溃,它可以从最近的存档点重启,并丢弃从最近检查点到崩溃之间的所有输出
在流处理框架的范围内,微批次与存档点方法提供了与批处理一样的恰好一次语义。但是,只要输出离开流处理器(例如,写入数据库,向外部消息代理发送消息,或发送电子邮件),框架就无法抛弃失败批次的输出了。在这种情况下,重启失败任务会导致外部副作用发生两次,只有微批次或存档点不足以阻止这一问题,我们需要确保事件处理的所有输出和副作用当且仅当处理成功时才会生效。分布式事务是一种解决方案,另外一种方式是幂等性(idempotence)
幂等操作是多次重复执行与单次执行效果相同的操作,例如,将键值存储中的某个键设置为某个特定值是幂等的(再次写入该值,只是用同样的值替代),而递增一个计数器不是幂等的(再次执行递增意味着该值递增两次)。在使用来自Kafka的消息时,每条消息都有一个持久的,单调递增的偏移量。将值写入外部数据库时可以将这个偏移量带上,这样你就可以判断一条更新是不是已经执行过了,因而避免重复执行
<完>