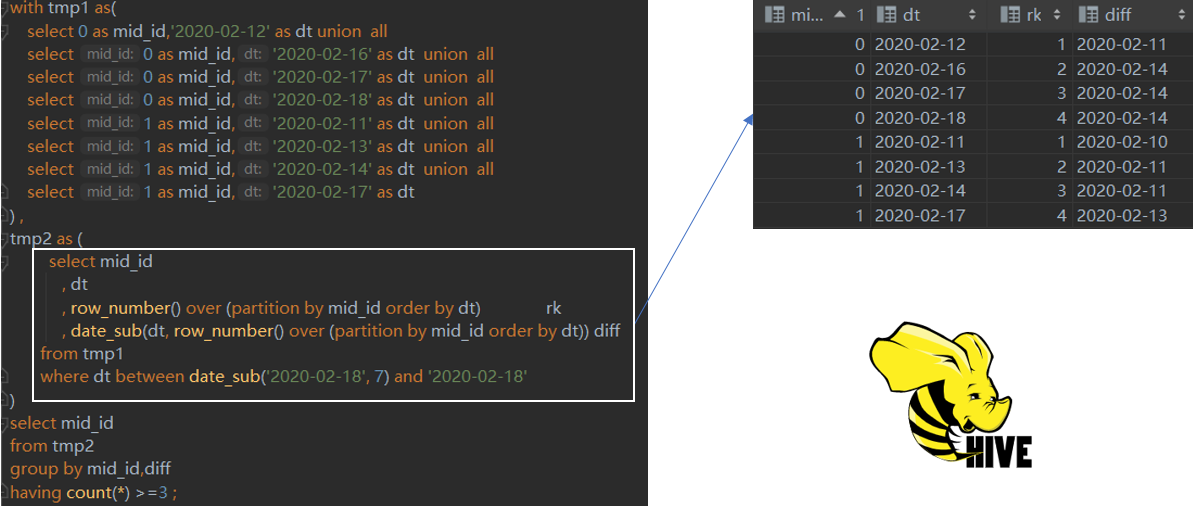
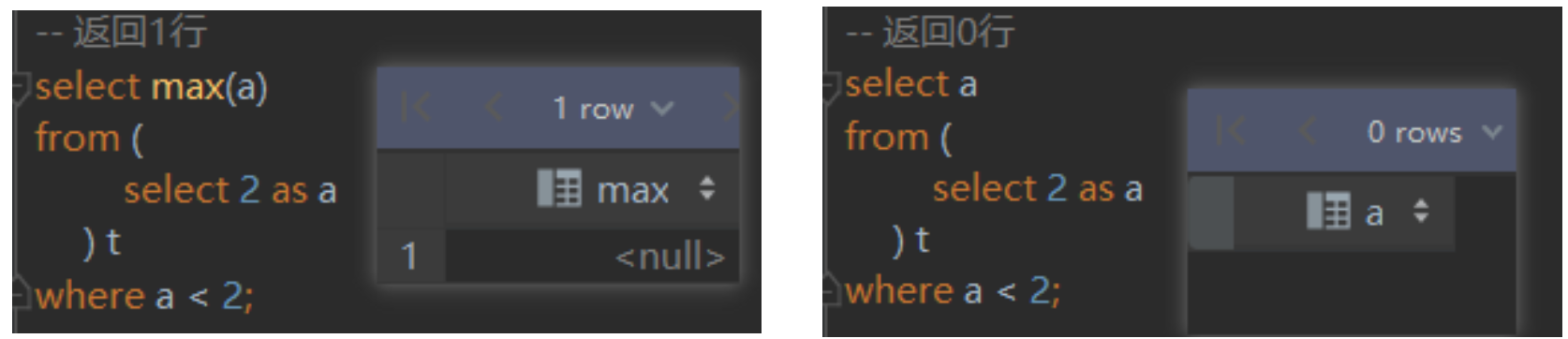
对于除数为0问题,优先使用nullif(a,0)函数来进行处理,但是该函数Hive2.2才有对应实现,nullif((a,b) 的语义在于,如果参数 a 等于 参数 b 那么,该函数返回 null
第二部分
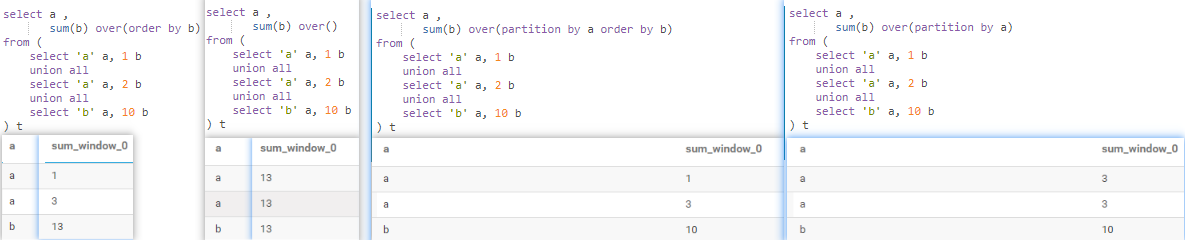
sum() + over()
不同引擎除0的结果比对
over() 全局求和
over(order by) 全局累积求和
over(partition by ) 分区内全局求和
over(partition by order by) 分区内累积求和
内网环境下,下面的脚本分别在 impala,hive,holo,pg , mysql ,执行以下,看下是什么情况
1 2 3 4 5 6 7 8 9 10 11 12
with tmp1 as ( select'a'as a,1as b unionall select'a'as a , 2as b unionall select'b'as b , 10as b ) select a , avg(b) over(partitionby a orderby b) x , sum(b) over(partitionby a orderby b) y from tmp1 ;
-- hive 语法 with tmp1 as( select'A;B;C'as name , 20as age ) select explode(split(name,';')) , age -- Only a single expression in the SELECT clause is supported with UDTF's -- 如果是多列,使用测斜视图语法 from tmp1 ; -- 如下(hive语法) with tmp1 as( select'A;B;C'as name , 20as age ) select name , age , col_x from tmp1 lateralview explode(split(name,';')) x as col_x ;
-- hive & impala with tmp1 as( select'abc大'as a unionall select'中abc'as a unionall select'abc小'as a ) select* from tmp1 -- where a rlike '大|中' -- 写法1 where a regxp '大|中'-- 写法2 -- 中abc -- abc大
-- holo & pg with tmp1 as( select'abc大'as a unionall select'中abc'as a unionall select'abc小'as a ) select* from tmp1 where a ~'大|中'
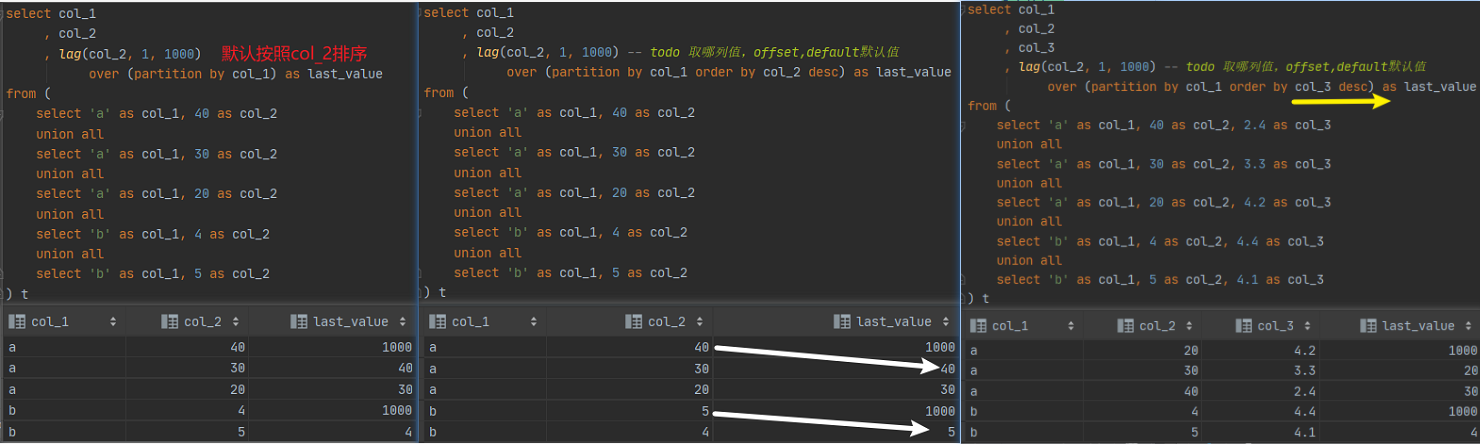
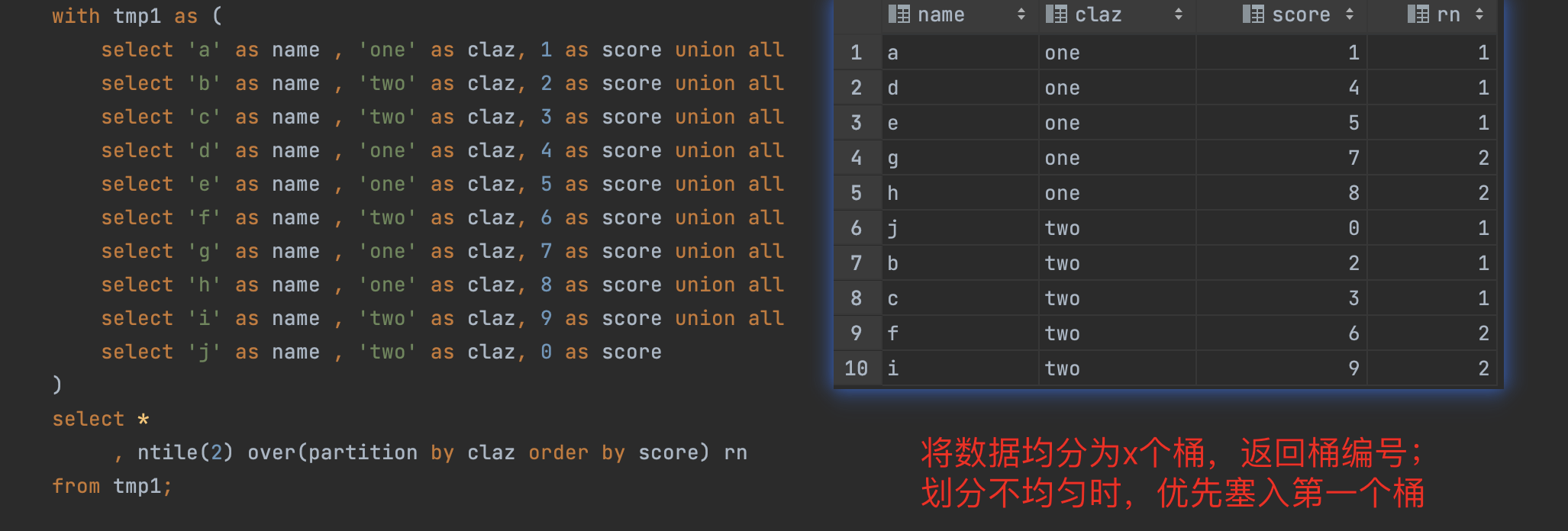
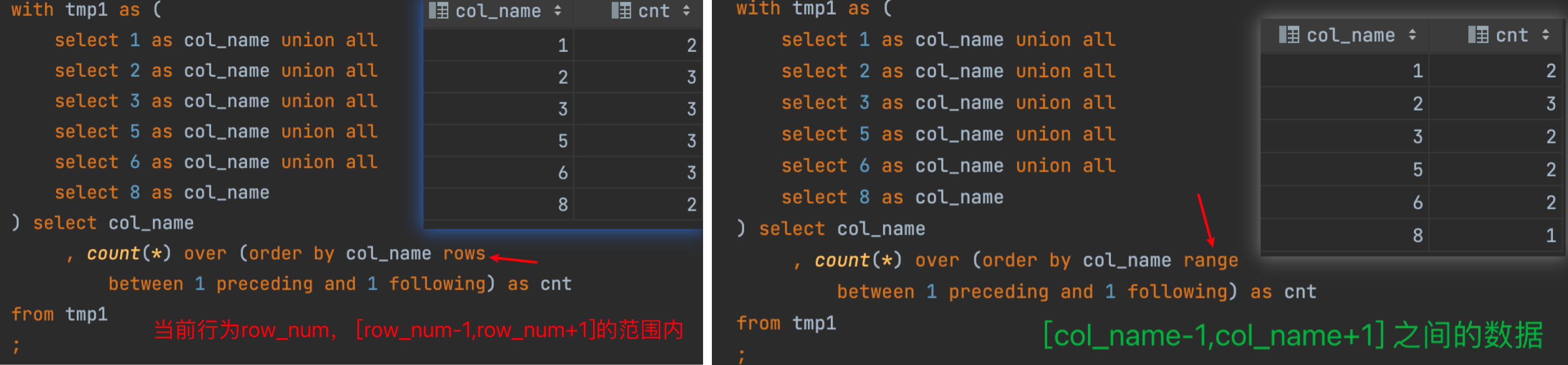
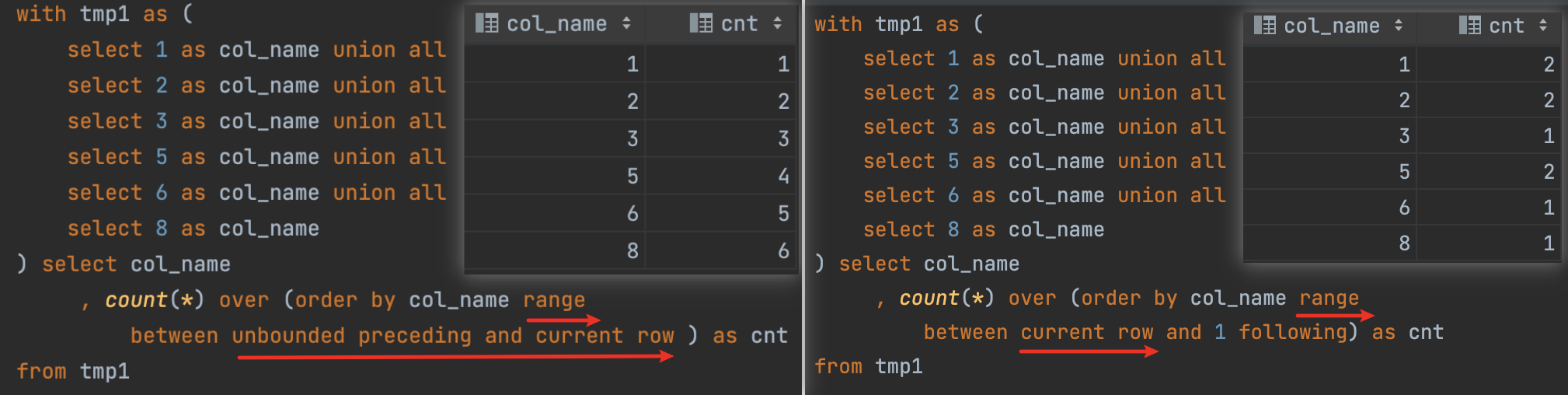
窗口函数的范围选择
注意 range 和rows之间的使用区别: rows计算的是行,range 计算的是值, preceding 往上,following 往下
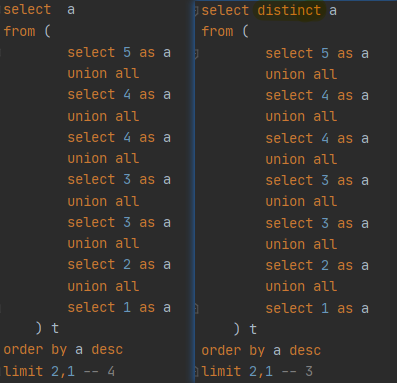
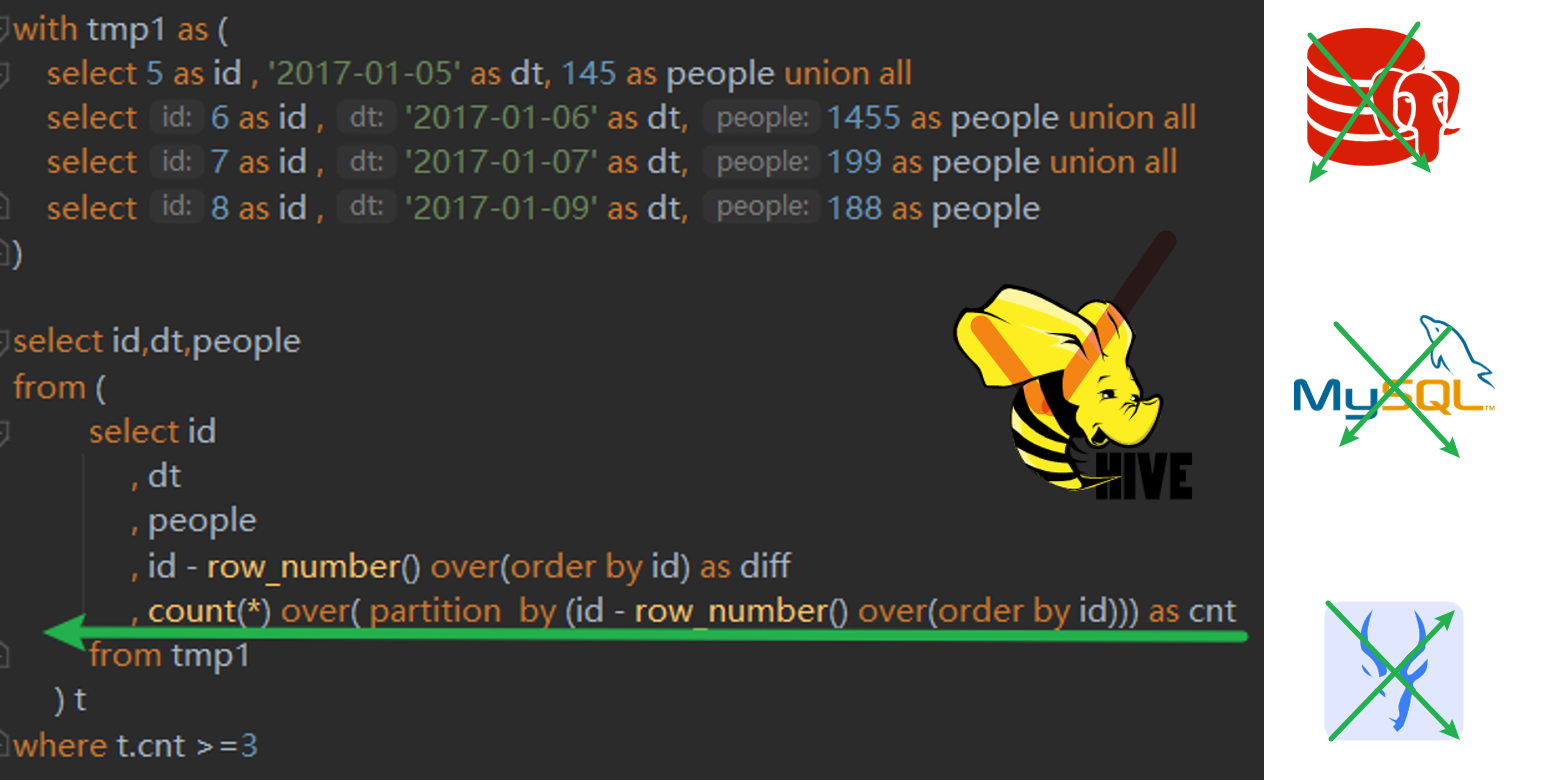
select a, count(*) as cnt from ( select5as a unionall select4as a unionall select4as a unionall select3as a unionall select3as a ) t groupby a having cnt >1;
上述的SQL在MySQL 和 hive中执行都是没问题的,在impala和postgreSQL报错 column "cnt" does not exist,需要下面的写法
1 2 3 4 5 6 7 8 9 10 11 12 13 14
select a, count(*) as cnt from ( select5as a unionall select4as a unionall select4as a unionall select3as a unionall select3as a ) t groupby a havingcount(*) >1;
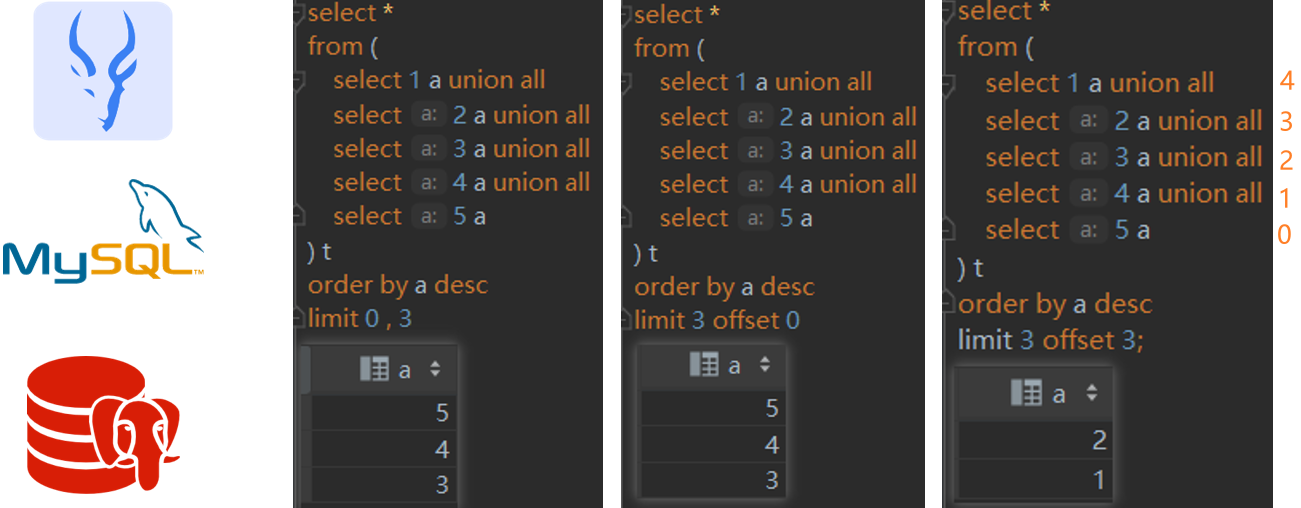
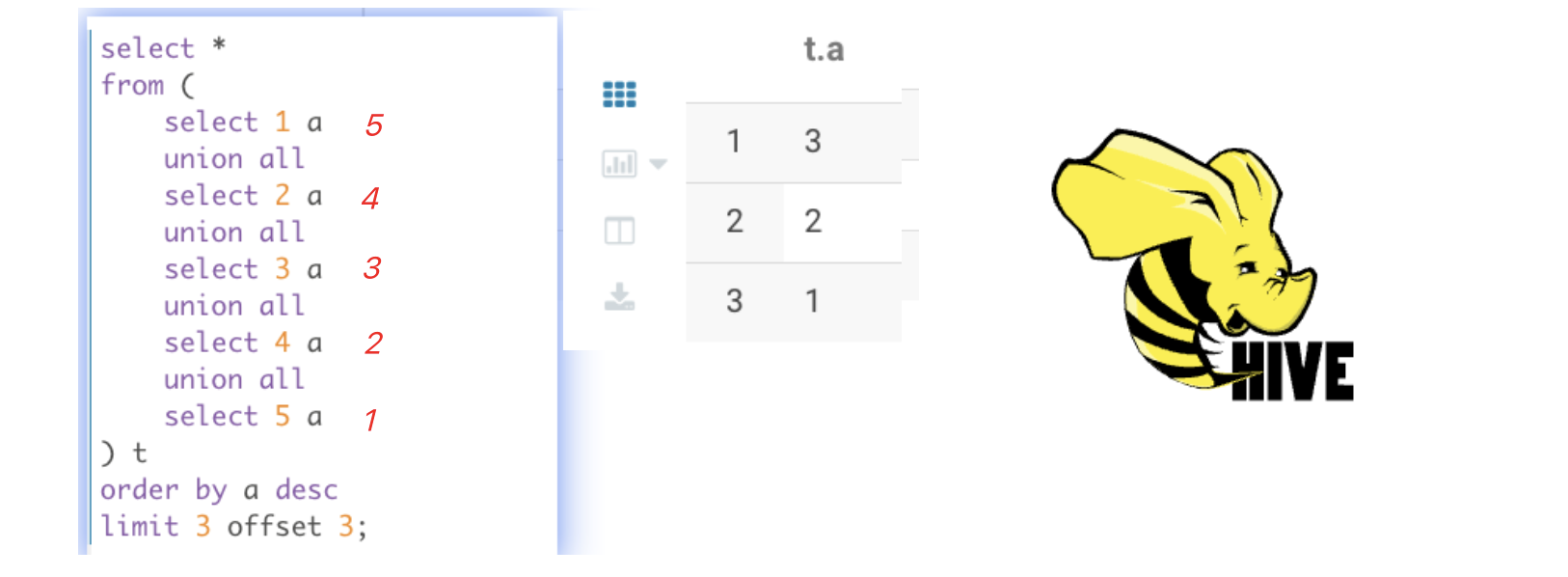
order by 字符串
1 2 3 4 5 6 7 8 9
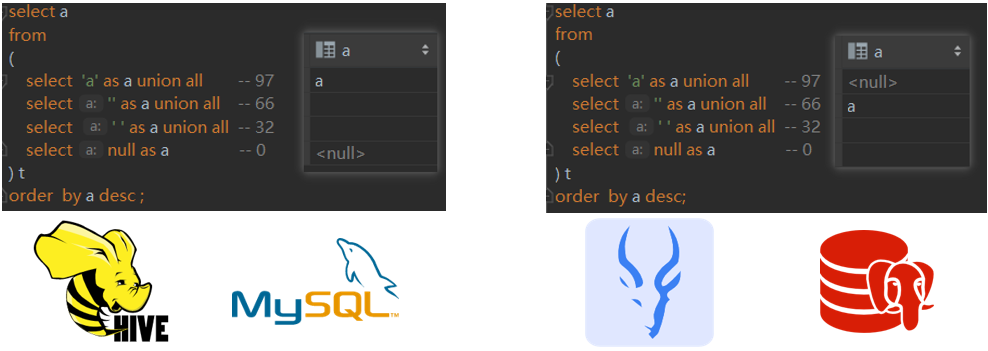
select a from ( select'a'as a unionall-- 97 select''as a unionall-- 66 select' 'as a unionall-- 32 selectnullas a -- 0 ) t orderby a desc ;
对于以上查询和排序,Hive和MySQL认为NULL是最小;Impala和PostgresSQL认为NULL最大,如果使用explain命令查看SQL的执行计划的话,会明显看到编译器会给SQL添加1个null first / null last的明亮,这个取决于具体的引擎,感兴趣的读者可以自己test下,比如Hive会将null设为最小,impala会将null设为最大
null,空串,空格 之间的排序关系
$24/5$的结果
DB/Program Language
value
Java / PostgreSQL
4
Hive / Impala / MySQL
4.8
窗口函数是否支持distinct
1 2 3 4 5 6 7
select A, B , count( distinct A) over() from ( select1as A ,'a'as B unionall select2as A ,'b'as B unionall select1as A ,'c'as B unionall select3as A ,'d'as B ) t
比如以上的SQL查询:Hive是支持的,Impala,MySQL,PostgreSQL暂时没有实现
窗口嵌套
窗口函数的嵌套,只Hive~2.1.1~中是支持的,PostgreSQL(window functions are not allowed in window definitions),MySQL,Impala 中只能多嵌套一层
不同的引擎对于窗口嵌套的支持
字符串写入数值类型
1 2 3 4 5 6
createtable if notexists business ( name strng, order_date string, cost float ); insertinto business values('xioaming','2021-08-22','');
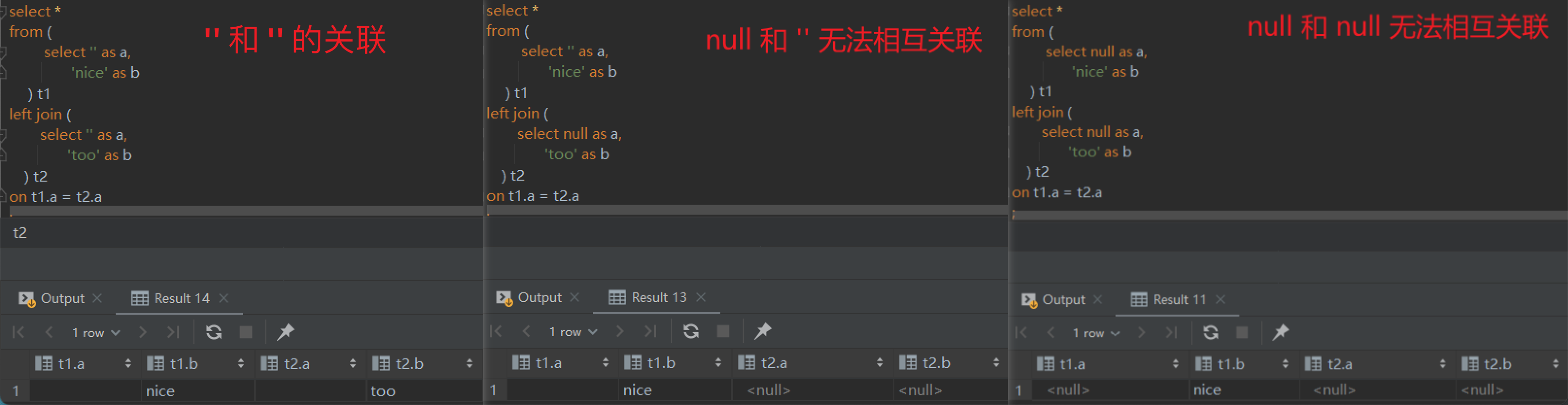
column_name not in (a): 出了会过滤掉值为a的记录,还会过滤掉 column_name为 null 的记录
1 2 3 4 5 6 7 8 9 10 11 12 13
with tmp1 as (-- select'a'as a unionall select'b'as a unionall select'c'as a unionall selectnullas a ) select* from tmp1 where a notin ('a') -- 结果返回 a,c
Impala 的模糊关联(非等值关联)
1 2 3 4 5 6 7 8 9 10 11 12
-- t2.name 是 t1.name 的子串的时候即返回 true ,注意顺序 with tmp1 as ( -- select'康恩贝/CONBA'as name, '2023-01-01'as live_date ) , tmp2 as ( -- select'CONBA'as name, '2023-01-01'as live_date ) select* from tmp1 t1 leftjoin tmp2 t2 on t1.live_date = t2.live_date and t1.name rlike t2.name
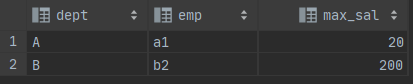
select e.emp_no, salary, last_name, first_name from employees e innerjoin salaries s on e.emp_no = s.emp_no where s.to_date ='9999-01-01' and s.salary = ( select s1.salary from salaries s1 innerjoin salaries s2 on s1.salary <= s2.salary where s1.to_date ='9999-01-01'and s2.to_date ='9999-01-01' groupby s1.salary havingcount(distinct s2.salary) =2 )
最大值只能小于等于最大值(出现1次);次大值只能小于等于最大值和本身(出现2次)
求薪资次高的员工
from tmp1 , tmp2 的本质
from tmp1 , tmp2 的本质就是 inner join的行为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
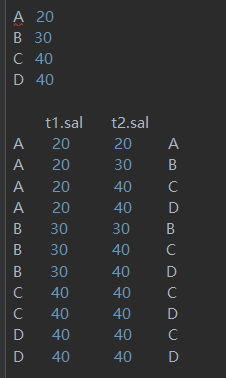
with tmp1 as (select'a'as name, 10as age unionall select'b'as name, 11as age unionall select'c'as name, 12as age ) , tmp2 as (select'c'as name, 'female'as sex unionall select'd'as name, 'male'as sex unionall select'e'as name, 'female'as sex ) select t1.name , t1.age , t2.sex from tmp1 t1 , tmp2 t2 where t1.name = t2.name
上述的SQL等同于下列SQL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
with tmp1 as (select'a'as name, 10as age unionall select'b'as name, 11as age unionall select'c'as name, 12as age ) , tmp2 as (select'c'as name, 'female'as sex unionall select'd'as name, 'male'as sex unionall select'e'as name, 'female'as sex ) select t1.name, t1.age, t2.sex from tmp1 t1 innerjoin tmp2 t2 on t1.name = t2.name
Hive 中强制 mapjoin
1 2 3 4
select/*+ mapjoin(t2)*/--强制指定关联方式 from t1 leftjoin t2 on t1.key= t2.key
return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Spark job failed because of out of memory.
ExecutorLostFailure (executor 10 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 15.3 GB of 15.3 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead
) select on_top_time as on_top_time , start_time as start_time , cast((unix_timestamp(on_top_time) - unix_timestamp(start_time)) /3600+1asint) as hours_id from tmp1
-- 原有的逻辑是: select A.id from A join B on A.id = B.id
-- 改进后的逻辑,第一部分,该部分查询不会有任何倾斜 select A.id from A join B on A.id = B.id where A.id <>1
-- 改进后的逻辑,第二部分,B.id=1的数据量很小,我们将其放入内存关联,在spark种叫广播关联,在hive中叫做 map-join select/*+ mapjoin(B)*/ A.id from A join B on A.id = B.id where A.id =1 and B.id =1
set hive.exec.dynamic.partition.mode=nonstrict; insert overwrite table target_table partition (date_id) select id as id , name as name , t1.date_id from (select date_add("2023-02-01", a.pos) as date_id from (select posexplode(split(repeat("@", datediff("2023-08-08", "2023-02-01")), "@")) -- 第一个日期终止日期,第二个日期起始日期, ) a ) t1 crossjoin (select* from target_table where date_id ='2023-08-09' ) t2